LongCat Video: Generate Coherent AI Videos Up to 15 Minutes Long

Share this post:
LongCat Video: Generate Coherent AI Videos Up to 15 Minutes Long
Update 2026: Looking for character avatars with lip-sync and 5-minute+ consistent identity? See our new LongCat Video Avatar guide for audio-driven avatar generation. The May 2026 LongCat-Video-Avatar 1.5 release adds Whisper-Large for lip sync across 99 languages and reduces inference to 8 steps.
Duration remains the limiting factor in AI video generation. Most systems cap at 5-10 seconds before temporal consistency breaks down. LongCat Video addresses this constraint by generating coherent content extending to 15 minutes, representing a 100x increase over typical capabilities.
The system from Meituan maintains visual consistency, narrative coherence, and technical quality across extended durations. Characters retain appearance throughout sequences, environments stay spatially consistent, and motion flows naturally without the discontinuities that plague shorter models when pushed beyond their limits.
Released as open-source software with commercial licensing, LongCat Video enables filmmakers to generate extended sequences suitable for complete scenes, short films, or narrative segments rather than brief clips requiring extensive stitching.
The Duration Problem in AI Video
Video generation systems face exponential complexity increases with duration. Each additional second requires maintaining consistency with all previous frames while generating new content. This compounds memory requirements, computational demands, and the challenge of preventing quality degradation.
Models trained on short clips learn patterns within those durations. Extending beyond training length introduces artifacts, discontinuities, and consistency failures. A model trained on 5 second clips might generate clean output for that duration but shows degradation at 10 seconds and collapses at 30 seconds.
The technical barrier stems from how diffusion models process temporal information. Attention mechanisms that maintain frame-to-frame consistency scale quadratically with sequence length. Doubling video duration quadruples computational requirements, creating practical limits on manageable length.
Previous approaches to longer videos typically concatenate multiple short generations or extend single clips autoregressively. Concatenation produces visible seams where clips join, with character appearance changes, lighting shifts, or environmental inconsistencies. Autoregressive extension accumulates errors, with quality degrading as sequences lengthen.
For filmmakers, this duration constraint limits AI video generation to supplementary roles. Brief establishing shots, reaction moments, or transitional elements work within 5-10 second windows. Complete scenes with narrative development require human-shot footage or extensive manual stitching of AI generated clips.
How LongCat Video Achieves Extended Duration
LongCat Video employs architectural innovations enabling coherent generation across extended timeframes. The system doesn't simply concatenate short clips but generates long sequences as unified temporal structures.
The hierarchical temporal modeling separates shortterm and longterm consistency mechanisms. Local attention maintains smooth motion and frame-to-frame coherence within short windows. Global attention preserves character appearance, environmental consistency, and narrative elements across the full sequence.
This separation allows efficient processing. Dense attention within local windows ensures temporal smoothness. Sparse attention across the full sequence maintains global consistency without quadratic computational scaling. The combined approach achieves both local and global coherence.
Memory management techniques enable processing of extended sequences within practical GPU memory constraints. Rather than loading entire sequences simultaneously, the system processes in overlapping segments that maintain consistency at boundaries. This windowing approach allows generation of arbitrarily long videos limited by time rather than memory.
The training strategy exposes the model to varying durations rather than fixed lengths. This curriculum helps the model learn temporal patterns that scale across different timeframes. The system understands both shortterm dynamics and longterm narrative structure.
Consistency mechanisms track characters, objects, and environmental elements across the full duration. Rather than treating each frame independently, the system maintains identity information ensuring the same character appears consistent throughout a 15 minute sequence.
Temporal Consistency Across Minutes
Maintaining consistency over minute scale durations requires addressing challenges that don't appear in shorter generations. LongCat Video implements specific mechanisms for extended temporal coherence.
Character consistency ensures that people appearing in the video maintain recognizable appearance throughout. Clothing, facial features, hairstyles, and body type remain stable across the full duration. This prevents the character drift that occurs when models treat distant frames as unrelated.
Environmental consistency maintains spatial relationships and scene properties. Room layouts stay consistent, lighting conditions remain stable unless intentionally changed, and object positions follow logical patterns. The scene doesn't reshape itself as the video progresses.
Motion continuity flows naturally across the extended timeline. Actions initiated early in the sequence complete appropriately later. Camera movements maintain coherent trajectories rather than jumping discontinuously. Object motion follows consistent physics throughout.
Narrative coherence allows story elements to develop over time. A character who picks up an object early in the sequence can be shown using it later. Emotional states progress logically rather than resetting randomly. Cause and effect relationships span the duration.
The lighting and atmosphere consistency prevents arbitrary shifts. Time of day changes happen gradually if at all. Weather conditions transition naturally rather than jumping between states. Color palettes remain coherent throughout sequences.
These consistency mechanisms operate simultaneously, maintaining coherence across visual, spatial, temporal, and narrative dimensions throughout extended generation.
Quality Maintenance at Length
Extended duration generation risks quality degradation as sequences lengthen. LongCat Video maintains consistent quality from first frame to final frame through several approaches.
The detail preservation mechanisms prevent progressive blurring or simplification that sometimes occurs in extended generation. Textures, fine details, and sharp edges maintain clarity throughout the sequence. The model doesn't sacrifice detail to maintain temporal consistency.
Motion quality remains smooth and natural across the full duration. Early frames don't exhibit higher quality motion than later frames. The temporal modeling ensures consistent motion realism throughout.
Resolution stability maintains consistent output dimensions and clarity. The video doesn't degrade to lower effective resolution as duration extends. Each frame maintains target quality standards.
Artifact prevention catches and corrects common failure modes before they compound. Rather than allowing errors to accumulate across frames, the system identifies and addresses issues maintaining clean output.
The computational allocation balances resources across the sequence. Rather than spending more computation on early frames and less on later ones, processing distributes evenly ensuring consistent quality throughout.
Testing across various prompts and scenarios demonstrates maintained quality at different duration targets. Whether generating 2 minutes or 12 minutes, quality metrics remain comparable rather than degrading with length.
Narrative and Scene Structure
The extended duration capability enables generation of content with actual narrative structure rather than isolated moments. LongCat Video supports story development across its generation window.
Scene composition allows multiple distinct moments within single generations. An introduction can establish setting, transition to character interaction, develop through action or dialogue, and conclude with resolution. This complete scene structure fits within the 15 minute capability.
Story beats develop naturally across the timeline. Setup elements in early sections pay off later. Character relationships evolve. Situations progress from beginning through middle to end. This narrative flow requires the temporal span that LongCat Video provides.
Emotional arcs play out over extended sequences. A character's emotional state can shift gradually throughout the video rather than existing in a single static state. This emotional development adds depth unavailable in brief clips.
Pacing variation becomes possible with sufficient duration. Sequences can include both fast paced action and slower contemplative moments. This rhythm creates more engaging content than constant pacing throughout.
Multiple location visits can occur within single generations. A character might start in one room, move to another space, then transition to a third location, all within a coherent sequence. This spatial variety enriches storytelling possibilities.
The narrative capabilities position LongCat Video for applications beyond brief clips. Short films, documentary segments, educational content, and commercial narratives all benefit from extended coherent generation.
Content Types and Applications
The 15 minute generation capability suits specific content categories where extended duration provides particular value. Understanding these applications helps identify appropriate use cases.
Short film production benefits directly from extended generation. While 15 minutes doesn't accommodate feature length, it suits short film formats. Filmmakers can generate complete narrative pieces rather than assembling clips.
Educational content often requires extended explanation and demonstration. Tutorial videos, documentary segments, and instructional content work well within the duration range. The consistent quality maintains professional appearance throughout.
Commercial and promotional content for products or services can develop complete narratives. Rather than brief teaser clips, brands can tell fuller stories about products, demonstrate use cases, or create atmospheric brand content.
Music videos naturally fit within the duration range, with most songs running 3-5 minutes. The extended capability allows complete music video generation with narrative development throughout.
Documentary segments and interview content benefit from extended uninterrupted generation. Subject explanations, demonstrations, or testimonials can develop without arbitrary duration constraints.
Previsualization for longer sequences becomes practical. Directors can generate extended previsualization content showing how complete scenes will unfold, supporting better production planning.
The content applications share common requirements: narrative development, consistent visual quality, and duration exceeding what typical AI video tools provide.
Technical Architecture Details
LongCat Video's architecture combines several components enabling extended generation. Understanding the technical approach helps developers integrate or extend the system.
The base model uses a diffusion transformer architecture processing video data. This foundation provides the generation capabilities, with modifications enabling extended temporal processing.
The hierarchical attention mechanism operates at multiple temporal scales. Fine grained attention handles frame-to-frame transitions. Medium scale attention maintains consistency within scenes. Coarse attention preserves elements across the full duration.
The memory efficient processing windows video into overlapping segments. Each segment generates with awareness of surrounding context through attention mechanisms spanning segment boundaries. This windowing enables processing of extended sequences without loading everything simultaneously.
Consistency tracking maintains identity information for characters, objects, and environmental elements. These embeddings propagate across the sequence, ensuring recognizable entities remain consistent throughout.
The training curriculum progressively increases sequence length. Models start learning on shorter videos, gradually extending to longer durations. This staged approach helps the model develop temporal understanding that scales.
Computational optimization through mixed precision, attention sparsity, and efficient memory management makes generation practical. Without these optimizations, 15 minute generation would require impractical computational resources.
Computational Requirements
Running LongCat Video requires substantial computational resources scaling with target duration. Understanding these demands helps plan practical deployment.
GPU memory requirements depend on target length and resolution. Generating 5 minute sequences at standard resolution requires approximately 40GB VRAM. Extending to 15 minutes increases memory needs proportionally. High end professional GPUs or multi GPU systems handle longer generations.
Generation time scales roughly linearly with duration. A 1 minute sequence might require 10-15 minutes processing on an A100 GPU. A 15 minute sequence extends this to several hours. This generation time remains practical for production workflows even if not interactive.
The computational scaling compares favorably to naive approaches. Processing a 15 minute sequence as a unified generation is more efficient than generating and stitching 180 separate 5 second clips. The integrated approach eliminates redundant computation at clip boundaries.
Cloud based processing provides alternatives for users without local GPU resources. Services offering GPU instances can handle generation, though longer sequences incur proportional costs.
The system supports variable duration targets. Users can generate 2 minutes, 7 minutes, or 15 minutes based on needs. Shorter targets complete faster, providing flexibility for different project requirements.
Batch processing isn't supported in the current implementation due to memory constraints. Multiple sequences require sequential processing rather than parallel generation.
Prompt Engineering for Extended Content
Generating coherent extended sequences requires different prompting approaches than brief clips. Effective use of LongCat Video demands understanding how to structure prompts for longer narratives.
Temporal structure should be explicit in prompts. Rather than describing single moments, prompts should outline progression: "Scene begins with character entering room, character examines environment, character discovers object, character reacts to discovery, scene ends with character leaving." This temporal roadmap guides generation.
Consistency elements need explicit specification. Character descriptions should be detailed enough to maintain recognition throughout: "tall woman with long red hair, wearing blue jacket and jeans, carrying black backpack." Specific details help consistency mechanisms maintain appearance.
Scene transitions require clear indication when location or situation changes occur. "The scene transitions from the office interior to the outdoor parking lot" signals spatial shifts that the model should handle coherently.
Pacing guidance helps the model distribute action appropriately across the duration. "Slowly, the character approaches" versus "Quickly, the character runs toward" provides timing information affecting motion generation.
Narrative beats should be sequenced logically. Setup elements establish context, development introduces complications or changes, resolution provides conclusion. This structure helps the model generate content that flows narratively.
The prompt detail level affects generation quality. More specific prompts with clear temporal structure produce better results than vague descriptions relying heavily on model interpretation.
Comparison with Existing Approaches
LongCat Video's extended duration capability differentiates it from other video generation systems. Understanding these differences helps identify when LongCat Video provides advantages.
Standard text-to-video models like Runway Gen3 or Pika generate 5-10 seconds. LongCat Video's 15 minute capability represents 100x duration increase. This isn't just quantitative difference but enables qualitatively different applications.
Systems like HoloCine focus on multi-shot coherence within shorter timeframes. LongCat Video emphasizes extended single sequence generation. These represent different approaches to temporal structure in generated video.
Concatenation-based methods stitch multiple short generations. LongCat Video generates extended sequences as unified temporal structures, avoiding the seam issues that plague concatenation approaches.
Autoregressive extension methods generate sequences frame-by-frame or clip-by-clip. LongCat Video's hierarchical approach maintains consistency more effectively across longer durations than autoregressive error accumulation allows.
The tradeoff involves computational cost. LongCat Video requires substantially more processing than generating 10 second clips. For applications needing extended duration, this cost becomes worthwhile. For brief moments, lighter systems suffice.
Licensing and Commercial Use
LongCat Video releases as open source software with licensing permitting commercial applications. Understanding the terms helps productions plan adoption.
The code is available on GitHub at github.com/meituan-longcat/LongCat-Video. The repository includes implementation, model weights, and documentation.
The licensing permits commercial use without separate commercial licenses or fees. Production companies can use LongCat Video in commercial projects, monetize generated content, and integrate the system into commercial workflows.
This commercial friendly licensing removes barriers for production adoption. Studios and independent filmmakers can deploy without licensing negotiations or ongoing fees.
The open source nature enables customization. Productions can modify the code for specific needs, finetune models on custom data, or integrate with proprietary tools.
Model weights are distributed through the project website at meituan-longcat.github.io/LongCat-Video. Standard model hosting and version control facilitate access and updates.
Community development benefits all users through shared improvements. Bug fixes, optimizations, and feature additions from the community enhance the system for everyone.
The open source commercial friendly approach positions LongCat Video as practical foundation for production deployment rather than research only demonstration.
Integration into Production Workflows
Practical use of LongCat Video requires understanding where extended generation fits within existing production processes.
Previsualization gains from extended generation capability. Directors can create minute scale previs showing complete scene flow rather than brief moment demonstrations. This supports better planning and decision-making.
Short film production can use LongCat Video for complete projects or substantial segments. The 15 minute capability suits common short film durations directly.
Commercial production for advertisements and promotional content benefits from extended narrative generation. Rather than assembling brief clips, complete commercial narratives generate as unified sequences.
Documentary segments and interview content can generate at appropriate lengths. Explanations, demonstrations, or testimonials develop completely within single generations.
The generation process involves prompting, processing, and review. Computational time means generations aren't interactive, but batch processing overnight or during other work enables practical integration.
Quality evaluation becomes more involved with extended content. Reviewing 15 minutes requires more time than checking 10 second clips. Efficient review processes become important for practical workflows.
The technology works best for content types where extended coherent generation provides value over assembled brief clips. Understanding this distinction helps identify appropriate applications.
Current Limitations and Considerations
LongCat Video achieves impressive extended generation but faces constraints affecting deployment. Understanding limitations helps set appropriate expectations.
The 15 minute maximum, while substantial, still falls short of feature length requirements. Short films and segments suit the capability, but longer formats require alternative approaches or multiple generations.
Resolution constraints exist similar to other video generation systems. Balancing resolution against duration and computational requirements means outputs may not achieve maximum desired resolution for all use cases.
Complex action sequences with rapid motion or intricate physical interactions may show artifacts even at shorter durations. The system performs best with moderate complexity content rather than extremely dynamic sequences.
Fine control over specific timing and action remains challenging. While prompts guide generation, precise timing of specific events or exact duration of particular actions doesn't always match intentions exactly.
Character consistency, while strong, isn't perfect across full 15 minute durations. Subtle appearance drift can occur in extended sequences, though typically remaining within acceptable ranges.
The generation time of several hours for maximum length content limits iteration speed. Testing different approaches or variations becomes time intensive compared to shorter generation systems.
Future Development Directions
Several research directions could extend LongCat Video capabilities and address current limitations.
Further duration extension beyond 15 minutes would support longer form content. Feature length generation remains distant, but 30 minute or hour long capabilities would expand applications significantly.
Resolution improvements while maintaining extended duration would benefit production quality. Balancing resolution against length represents ongoing optimization challenge.
Interactive refinement allowing users to modify specific portions of generated sequences would improve practical utility. Rather than regenerating entire sequences for adjustments, targeted modifications would streamline workflows.
Multi scene generation with explicit scene transitions would support more complex narrative structures. Currently, generation works best for single coherent scenes rather than multiple distinct scenes.
Character and environment persistence across separate generations would enable episodic content. Maintaining consistent character appearance across multiple 15 minute generations would support serialized storytelling.
Realtime or near real time generation remains aspirational but would transform applications. Significant speedups through architectural optimization or hardware acceleration could enable interactive workflows.
Practical Applications for Filmmakers
Ready to start generating? The full step by step guide to LongCat Video on the platform:
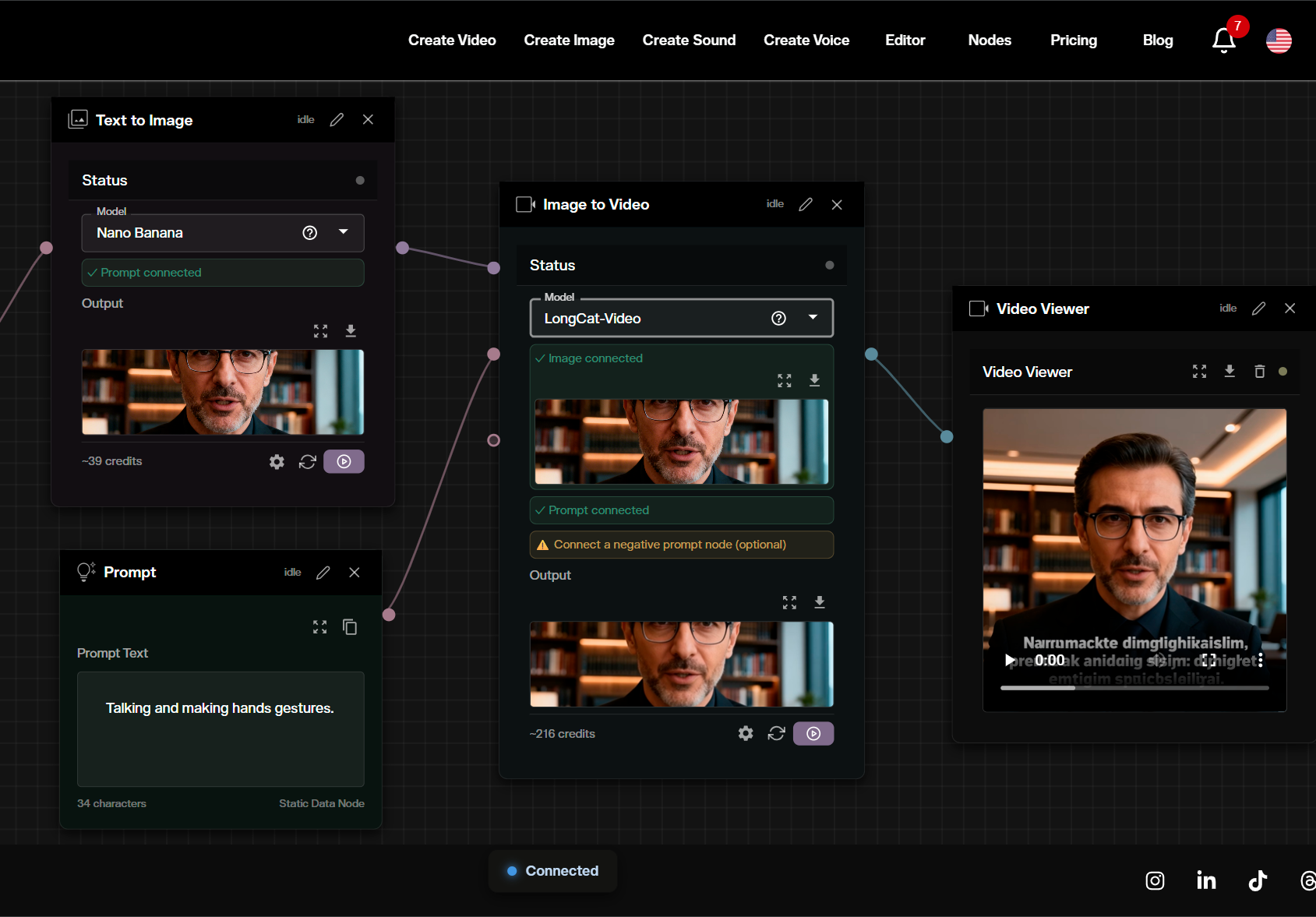
Understanding specific applications helps filmmakers identify when LongCat Video provides practical value.
Music video production suits the duration range and benefits from coherent narrative generation. Complete videos generate with consistent visual treatment throughout.
Short narrative films under 15 minutes can generate as complete pieces. Student films, festival submissions, and online content work within the capability.
Extended B-roll and establishing sequences for longer productions can generate without manual stitching. This supplemental footage integrates into traditionally shot content.
Proof-of-concept and pitch materials benefit from extended coherent generation. Showing investors or collaborators complete scene flow rather than brief moments communicates vision more effectively.
Educational content and tutorials can generate at appropriate lengths for topic coverage. Explanations and demonstrations develop completely within single generations.
Experimental and artistic video work explores the aesthetic possibilities of extended AI generation. Artists can create pieces that leverage the unique qualities of the technology.
The applications share common threads: benefiting from extended coherent generation and fitting within the 15 minute duration window.
Conclusion
LongCat Video addresses a fundamental constraint in AI video generation by extending practical duration from seconds to minutes. The 15 minute capability represents substantial progress toward usable AI generated content for filmmaking applications.
The system maintains consistency across visual, temporal, narrative, and quality dimensions throughout extended generation. Characters remain recognizable, environments stay coherent, motion flows naturally, and quality persists from first frame to last.
The open source release with commercial licensing enables production adoption without licensing barriers. Filmmakers can deploy the technology, generate commercial content, and integrate into workflows without restrictions beyond computational requirements.
Current applications suit short films, music videos, commercial content, educational materials, and previsualization where extended coherent generation provides value. As the technology continues developing, supported durations and capabilities will likely expand.
The temporal barrier in AI video generation hasn't disappeared but has shifted dramatically. What once capped at 10 seconds now extends to 15 minutes. This progression continues the trend toward practical AI generated content suitable for filmmaking rather than brief demonstrations.
For filmmakers exploring AI tools, LongCat Video represents progress toward content duration supporting actual storytelling rather than brief moments. The extended temporal window opens applications previously impractical with shorter generation systems.


Resources:
- Project Website: https://meituan-longcat.github.io/LongCat-Video/
- GitHub Repository: https://github.com/meituan-longcat/LongCat-Video
- Technical Paper: Available on project website
- Demo Videos: Project website showcases various duration examples
- License: Open source with commercial use permitted
Continue Reading



Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Google Veo 3.1
- Kling 3.0 Pro
- LTX 2.3
- Happy Horse 1.0
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace