VideoCanvas: Revolutionary Unified Video Generation System

Image from VideoCanvas research paper (arXiv 2510.08555)
Share this post:
VideoCanvas: Breakthrough Research Unifies All Video Generation Tasks in Single Framework
Researchers from Kuaishou Technology's Kling Team and The Chinese University of Hong Kong (CUHK) have unveiled VideoCanvas, a revolutionary system that unifies multiple video generation tasks under a single, elegant framework. Published October 9, 2025, on arXiv, the research introduces arbitrary spatiotemporal video completion, a paradigm that naturally integrates image to video, inpainting, outpainting, camera control, scene transitions, and video extension into one cohesive approach.
VideoCanvas represents a fundamental shift in how AI video generation systems handle control and conditioning. Rather than building separate models or fine tuning for each task, the system achieves precise frame level control through innovative temporal positioning without adding any new parameters to the base model. The results demonstrate capabilities that significantly outperform existing methods across diverse video generation scenarios.
The research addresses a core technical challenge that has limited previous video generation systems: temporal ambiguity in latent video diffusion models. By solving this fundamental problem, VideoCanvas enables pixel frame aware control that was structurally difficult in earlier approaches.
Note: The full VideoCanvas research paper and code are available as open source resources. However, specific licensing terms for commercial use have not been explicitly stated in the initial release. Researchers and developers should review the repository for licensing updates before commercial deployment.
What VideoCanvas Accomplishes: Unified Video Completion
VideoCanvas introduces the task of arbitrary spatiotemporal video completion. Users can place patches or images at any spatial location and timestamp within a video canvas, similar to painting on a timeline. The system then generates coherent video that respects all provided conditions while filling in the unspecified regions.
This flexible formulation naturally unifies many existing controllable video generation tasks:
Image to video generation. Provide a single frame at the beginning, middle, or end, and VideoCanvas generates surrounding video content.
Video inpainting. Specify boundary frames or patches, and the system fills missing regions with coherent motion and content.
Video outpainting. Extend video spatially beyond original frame boundaries while maintaining consistency.
First Last Frame interpolation. Generate smooth transitions between two specified frames at any temporal distance.
Camera control. Simulate camera movements like zoom, pan, and tracking through progressive frame manipulation.
Scene transitions. Create smooth, cinematic transitions between different visual contexts.
Video extension. Extend short clips to significantly longer durations, including minute length looping videos.

Previous systems required separate models or specialized training for each capability. VideoCanvas handles all scenarios through the same underlying mechanism, making it genuinely unified rather than merely multi task.
The Technical Innovation: Solving Temporal Ambiguity
The key technical challenge VideoCanvas addresses stems from how modern video diffusion models work. These systems use Variational Autoencoders (VAEs) to compress video into latent representations before generation. Causal VAEs compress multiple pixel frames into single latent representations, creating temporal ambiguity that makes precise frame level conditioning structurally difficult.
When you want to condition on a specific frame at a particular timestamp, the compression process makes it unclear exactly where that frame maps in the latent space. This ambiguity prevented earlier systems from achieving pixel frame aware control.
VideoCanvas solves this with a hybrid conditioning strategy that decouples spatial and temporal control:
Spatial Control via Zero Padding
For spatial placement, VideoCanvas uses zero padding to position conditional patches precisely within the canvas. This approach is elegant because it requires no additional parameters or training. The system simply places your conditioning content at the specified location and pads unspecified regions with zeros, which the diffusion process then fills with generated content.
This zero padding strategy handles arbitrary patch sizes and positions naturally. Whether you provide a small object in one corner or multiple large patches scattered across the frame, the same mechanism applies.
Temporal Control via Temporal RoPE Interpolation
The temporal dimension requires more sophisticated handling due to the VAE ambiguity problem. VideoCanvas introduces Temporal RoPE Interpolation, which assigns each condition a continuous fractional position within the latent sequence.
RoPE (Rotary Position Embedding) is a technique for encoding position information in transformer models. By interpolating RoPE values, VideoCanvas can specify precisely where in time each condition should influence generation, even though the VAE compresses multiple frames into each latent representation.
This resolves the temporal ambiguity and enables pixel frame aware control on a frozen backbone. The system doesn't require fine tuning the VAE or adding new parameters. It works with existing pretrained models, making it broadly applicable.
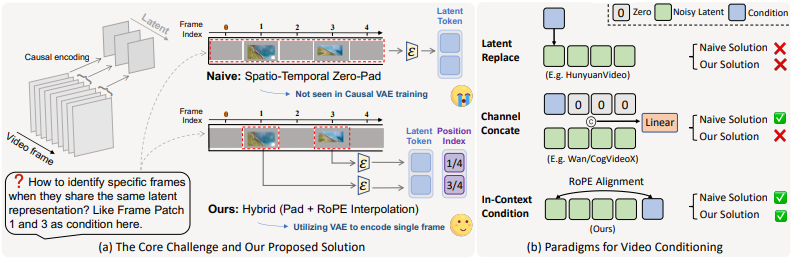
In Context Conditioning: The Foundation
VideoCanvas adapts the In Context Conditioning (ICC) paradigm to fine grained control tasks. ICC treats conditioning information as additional context provided alongside the generation target, similar to how large language models use prompts.
Rather than encoding conditions through separate channels or attention mechanisms, ICC simply concatenates conditional frames with the frames to be generated. The model learns to distinguish between provided context and regions requiring generation through position information and masking.
This approach offers several advantages:
Zero additional parameters. The same model weights handle both conditional and unconditional generation.
Flexible conditioning. Any number of conditions at any positions can be provided without architectural changes.
Unified training. A single training procedure covers all conditioning scenarios rather than requiring task specific fine tuning.
Generalization capacity. The model can handle conditioning patterns it never saw during training by leveraging its understanding of spatiotemporal relationships.
VideoCanvas extends ICC to handle the precise frame level conditioning required for arbitrary spatiotemporal completion through its hybrid spatial and temporal control mechanisms.
Practical Applications: What VideoCanvas Enables
The unified framework enables diverse creative applications through simple conditioning variations:
Image to Video at Any Timestamp
Unlike conventional image to video systems that only condition on the first frame, VideoCanvas accepts images at any timestamp. Provide a frame in the middle, and it generates both preceding and following video. Condition on the last frame, and it generates video leading to that conclusion.
This flexibility enables new storytelling approaches. Design a climactic moment, then have the system generate the buildup. Specify key story beats at different timestamps and let VideoCanvas fill the transitions.

Advanced Video Inpainting
VideoCanvas handles sophisticated inpainting scenarios where objects move through the scene. Traditional video inpainting often struggles with complex motion patterns or large missing regions. VideoCanvas's unified approach maintains coherence even when filling substantial spatiotemporal volumes.

The system can inpaint moving objects, remove unwanted elements across time, or fill regions where camera obstruction temporarily blocked the view. The results maintain consistent motion, lighting, and perspective throughout.
Cinematic Camera Control
VideoCanvas simulates camera movements through progressive frame manipulation on the spatiotemporal canvas. By systematically shifting or scaling content across frames, it creates zoom in, zoom out, pan left, pan right, pan up, and pan down effects.

This camera control doesn't require 3D scene understanding or depth estimation. The system achieves convincing camera motion purely through 2D manipulation of the video canvas, making it computationally efficient and broadly applicable.
The research demonstrates minute level videos with smooth, professional camera movements generated entirely through this canvas based approach.
Scene Transitions
VideoCanvas creates smooth transitions between different visual contexts. Provide starting and ending scenes at different timestamps, and the system generates cinematic transitions that bridge the gap.

Unlike simple cross dissolves or cuts, VideoCanvas transitions can incorporate motion, perspective changes, and content morphing that make the shift feel intentional and artistic rather than abrupt.
This capability particularly benefits music video creation, experimental film, and any application requiring creative visual flow between disparate scenes.
Video Extension to Minute Length
One of VideoCanvas's most impressive demonstrations extends short video clips to minute long durations while maintaining visual consistency. The system can extend narratives interactively by accepting text prompts that guide the extension direction.

For seamless looping, VideoCanvas transitions the final generated segment back to the initial clip. Unlike simple first last frame looping that often causes stuttering due to mismatched motion, VideoCanvas uses the last clip's motion information to ensure smooth, consistent, truly seamless loops.
The research shows examples exceeding 1,000 frames, demonstrating that the approach scales to substantial durations without quality degradation or drift.

VideoCanvasBench: New Evaluation Framework
To properly evaluate arbitrary spatiotemporal video completion capabilities, the researchers developed VideoCanvasBench, the first benchmark specifically designed for this task. The benchmark covers both intra scene fidelity and inter scene creativity.
Intra Scene Fidelity
These tests measure how well systems maintain consistency within a single scene context. Metrics include:
Temporal coherence. Frame to frame consistency in motion, appearance, and lighting.
Spatial alignment. Accurate positioning and scale of objects across frames.
Physical plausibility. Realistic motion patterns and object interactions.
Detail preservation. Maintaining fine details from conditional frames in generated content.
Inter Scene Creativity
These tests evaluate systems' ability to generate creative, coherent content when bridging different visual contexts:
Semantic transitions. Meaningful visual flow between disparate scenes.
Style consistency. Maintaining or appropriately transitioning stylistic elements.
Narrative coherence. Logical progression in content across scene boundaries.
Creative quality. Interesting, engaging visual solutions rather than generic transitions.
VideoCanvasBench provides standardized evaluation protocols that enable fair comparison between different approaches and track progress in arbitrary spatiotemporal video completion capabilities.
The researchers plan to release this benchmark publicly, enabling the research community to build on their work and drive further improvements.
Experimental Results: Significant Performance Gains
Experiments demonstrate that VideoCanvas significantly outperforms existing conditioning paradigms across the VideoCanvasBench suite. The improvements span both intra scene fidelity metrics and inter scene creativity measures.
Key findings include:
Superior temporal consistency. VideoCanvas maintains coherence across longer temporal spans than comparison methods.
Precise spatial control. Conditional patches influence generation at exactly specified locations without bleeding or drift.
Better motion quality. Generated motion patterns appear more natural and physically plausible.
Stronger creative transitions. Scene transitions show more interesting, cinematically appropriate solutions.
Robust generalization. The system handles conditioning patterns not explicitly present in training data.
The zero parameter approach means these improvements come without architectural complexity or computational overhead compared to base models. VideoCanvas achieves better control through smarter conditioning rather than model expansion.
Open Source Availability and Research Access
The VideoCanvas research team has made their work available to the broader research community:
arXiv paper. Complete technical documentation at arXiv:2510.08555 detailing the method, experiments, and results.
Project page. Comprehensive showcase at https://onevfall.github.io/project_page/videocanvas/ with visual examples and demonstrations.
GitHub repository. Code and implementation details at https://github.com/KwaiVGI/VideoCanvas for researchers and developers.
Hugging Face integration. The paper is featured on Hugging Face Papers for community discussion and collaboration.
This open approach accelerates research progress by enabling other teams to build on the work, validate results, and extend the framework to new applications.
Commercial Use Considerations
Important: As of the October 2025 release, specific licensing terms for commercial use have not been explicitly detailed in the repository or paper. The code is marked as available for research purposes, but commercial deployment requires careful review of licensing terms.
Organizations interested in commercial applications should:
Monitor the GitHub repository for licensing updates and commercial use guidelines.
Contact the research team directly through the provided email (minghongcai@link.cuhk.edu.hk) for collaboration or commercial licensing inquiries.
Review Kuaishou's broader licensing policies for their AI technologies and Kling platform integrations.
The distinction between research availability and commercial licensing is common in AI research releases. Teams typically provide open access for academic and research purposes while maintaining separate commercial licensing structures.
The Kuaishou and CUHK Collaboration
VideoCanvas emerges from collaboration between Kuaishou Technology's Kling Team and MMLab at The Chinese University of Hong Kong. This partnership combines industry expertise in video generation deployment with academic research excellence in computer vision and machine learning.
Kuaishou Technology and the Kling Platform
Kuaishou Technology is a major Chinese technology company operating short video and live streaming platforms. Their Kling AI platform provides state of the art video and image generation capabilities to content creators.
The Kling Team has been at the forefront of generative AI research, producing several influential papers and models in video generation. VideoCanvas represents their continued push toward more flexible, controllable video generation systems.
Kuaishou's practical experience deploying AI video generation at scale informs the research priorities. The challenges of supporting diverse user needs and creative workflows drive technical innovations like VideoCanvas's unified framework.
CUHK MMLab
The Multimedia Laboratory at The Chinese University of Hong Kong is renowned for computer vision research, particularly in video understanding, generation, and editing. The lab has produced numerous influential works in these domains.
The academic partnership brings rigorous research methodology, theoretical foundations, and connections to the broader research community. CUHK researchers ensure the work meets high scientific standards while remaining grounded in practical applications.
This industry academic collaboration exemplifies how combining deployment experience with research expertise produces innovations that are both technically sophisticated and practically useful.
Implications for Filmmakers and Content Creators
VideoCanvas's unified framework has significant implications for video production workflows and creative possibilities:
Simplified Production Pipelines
Rather than using different tools or models for image to video, inpainting, camera control, and transitions, creators can work within a single framework. This simplification reduces technical complexity and learning curves.
Enhanced Creative Control
The ability to specify conditions at arbitrary positions and timestamps provides unprecedented control over generated content. Creators can guide generation precisely where needed while letting the system handle other regions.
Rapid Iteration
VideoCanvas's zero parameter approach and unified framework enable faster experimentation. Testing different conditioning patterns or extending sequences doesn't require model switching or retraining.
Cost Efficiency
Unified frameworks reduce computational requirements compared to running multiple specialized models. Organizations can deploy fewer systems while covering more use cases.
New Creative Possibilities
Arbitrary spatiotemporal conditioning enables creative approaches that weren't feasible with previous systems. Designing key moments and generating connective content opens new storytelling methodologies.
Technical Details: How the System Works
For technically oriented readers and researchers, understanding VideoCanvas's implementation provides insights into its capabilities and potential extensions.
Architecture Foundation
VideoCanvas builds on latent diffusion models, which have become the dominant architecture for high quality video generation. The system works in the compressed latent space rather than directly in pixel space, enabling efficient processing of high resolution, long duration videos.
The base architecture is transformer based, leveraging attention mechanisms to model spatiotemporal relationships across the video canvas. This allows the system to capture long range dependencies in both space and time.
Conditioning Mechanism
The hybrid conditioning strategy separates spatial and temporal control:
Spatial conditioning uses zero padding to place conditional content at specified canvas locations. The diffusion process naturally fills zero padded regions while respecting provided content.
Temporal conditioning applies Temporal RoPE Interpolation to position conditions precisely in the latent temporal sequence. This resolves the VAE's temporal compression ambiguity.
The combination enables pixel frame aware control without architectural modifications or additional parameters.
Training Approach
VideoCanvas trains on diverse video data covering various scenes, motions, and content types. The training process exposes the model to many different conditioning patterns, teaching it to respect provided context while generating coherent completions.
Critically, this training is unified across all tasks. The model doesn't learn separate capabilities for inpainting, camera control, and transitions. Instead, it learns general spatiotemporal completion that naturally handles all scenarios.
Inference Process
During inference, users specify:
Canvas dimensions. Spatial resolution and temporal duration of the target video.
Conditional content. Patches or frames to be respected during generation.
Spatial positions. Where each condition should appear in the canvas.
Temporal positions. When each condition should occur in the timeline.
The system then generates video that respects all conditions while coherently filling unspecified regions. Multiple generation passes can refine results or extend duration further.
Comparison to Related Work
VideoCanvas builds on and extends several lines of research in controllable video generation:
Versus Separate Task Specific Models
Traditional approaches train separate models for image to video, inpainting, interpolation, and other tasks. VideoCanvas unifies these through a single framework, reducing complexity and enabling seamless combination of capabilities.
The unified approach also enables conditioning patterns that span multiple traditional tasks, like simultaneous inpainting and camera control, which would require complex pipeline coordination with separate models.
Versus Multi Task Learning Approaches
Some systems train single models on multiple tasks but treat each as distinct during inference. VideoCanvas goes further by framing all scenarios as instances of arbitrary spatiotemporal completion, a more fundamental formulation.
This deeper unification means the model truly understands the underlying task structure rather than memorizing different operational modes.
Versus ControlNet Style Conditioning
ControlNet and similar approaches add conditioning through additional network modules. VideoCanvas achieves comparable or superior control without any added parameters, making it more efficient and easier to integrate with existing models.
The zero parameter design also means VideoCanvas can be applied to any compatible base model without architectural modifications.
Limitations and Future Directions
Like all research systems, VideoCanvas has limitations that point toward future improvements:
Resolution and Duration Constraints
Current implementations work within practical resolution and duration limits imposed by computational resources. While the approach scales in principle, generating very high resolution, very long duration videos requires substantial compute.
Future work will likely focus on efficient scaling techniques that extend capabilities while managing computational costs.
Semantic Understanding
VideoCanvas operates primarily through learned spatiotemporal patterns rather than deep semantic understanding. While results are impressive, the system doesn't truly understand scene meaning, object identities, or narrative structure.
Integrating stronger semantic reasoning could enable more intelligent completion decisions, especially for complex creative tasks requiring understanding of content meaning.
Physical Consistency
While VideoCanvas generates plausible motion and interactions, it doesn't enforce physical laws or consistency rigorously. Objects might violate physics in subtle ways that humans notice.
Incorporating physical simulation or constraints could improve realism for applications requiring strict physical accuracy.
User Interface Challenges
The canvas based paradigm is powerful but requires thoughtful interface design for practical use. Specifying arbitrary spatiotemporal conditions through standard video editing tools can be cumbersome.
Developing intuitive interfaces that leverage VideoCanvas's flexibility without overwhelming users represents an important direction for practical deployment.
Impact on AI Video Generation Research
VideoCanvas contributes several important ideas to AI video generation research that will likely influence future work:
Unified Task Formulation
The arbitrary spatiotemporal completion formulation provides an elegant way to think about diverse video generation tasks. This conceptual unification helps researchers identify common structures and develop more general solutions.
Zero Parameter Control
Demonstrating that sophisticated control can be achieved without architectural modifications or additional parameters challenges assumptions about what requires model expansion versus clever conditioning.
Temporal Ambiguity Solutions
The Temporal RoPE Interpolation technique provides a template for addressing temporal ambiguity issues that affect many video generation systems. Other researchers can adapt this approach to their architectures.
Benchmark Development
VideoCanvasBench establishes evaluation standards for arbitrary spatiotemporal video completion. Having shared benchmarks accelerates progress by enabling fair comparisons and identifying areas needing improvement.
Getting Started with VideoCanvas Research
Researchers and developers interested in exploring VideoCanvas can access multiple resources:
Read the paper. The full technical paper at arXiv:2510.08555 provides comprehensive methodology and experimental details.
Explore the project page. Visual demonstrations at https://onevfall.github.io/project_page/videocanvas/ showcase capabilities and results.
Review the code. The GitHub repository at https://github.com/KwaiVGI/VideoCanvas contains implementation details.
Contact the team. For questions, collaboration, or communication, reach out to lead author Minghong Cai at minghongcai@link.cuhk.edu.hk.
The research team has expressed openness to collaboration and discussion, making this an accessible project for those wanting to build on the work.
Check our pricing plans to access the latest AI video generation capabilities as research advances like VideoCanvas become integrated into production tools.
What This Means for AI FILMS Studio Users
Research breakthroughs like VideoCanvas directly influence the capabilities we integrate into AI FILMS Studio. While VideoCanvas itself is a research system, the underlying principles and techniques inform our platform's evolution:
Unified workflows. We're working toward more unified video generation experiences that seamlessly handle diverse tasks.
Precise control. Techniques for frame level conditioning help us provide you with finer control over generated content.
Extended durations. Research into minute length generation guides our work on supporting longer video formats.
Cinematic capabilities. Camera control and transition techniques directly benefit our tools for creating professional video content.
As VideoCanvas and similar research matures, expect to see these capabilities integrated into production ready tools accessible through AI FILMS Studio.


Key Takeaways About VideoCanvas
Unified framework. VideoCanvas integrates image to video, inpainting, outpainting, camera control, transitions, and extension under a single paradigm.
Zero new parameters. Achieves sophisticated control without architectural modifications or model expansion.
Temporal RoPE Interpolation. Solves temporal ambiguity in latent video diffusion models through continuous fractional positioning.
Arbitrary spatiotemporal conditioning. Users can place conditions at any canvas location and timestamp.
Minute length videos. Demonstrates successful extension of short clips to over 1,000 frames with consistency.
Open source research. Paper, code, and demonstrations are publicly available for research purposes.
Commercial use unclear. Specific licensing for commercial deployment has not been detailed as of initial release.
Kuaishou and CUHK collaboration. Combines industry deployment expertise with academic research excellence.
New benchmark. VideoCanvasBench provides standardized evaluation for arbitrary spatiotemporal video completion.
Significant performance gains. Outperforms existing conditioning paradigms across diverse video generation scenarios.
VideoCanvas represents a major step forward in flexible, controllable video generation. Its unified approach and elegant technical solutions set new standards for what AI video systems can accomplish. As the research community builds on this work, expect continued rapid progress in making sophisticated video generation accessible and practical for creative professionals.
Sources and Additional Reading
VideoCanvas arXiv Paper (2510.08555)
VideoCanvas Official Project Page
Continue Reading



Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Google Veo 3.1
- Kling 3.0 Pro
- LTX 2.3
- Happy Horse 1.1
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace