LiveEdit: Real Time Streaming Video Editing, Open Source

Share this post:
LiveEdit: Real Time Streaming Video Editing, Open Source
LiveEdit is an open source video editing model that processes and edits video chunk by chunk at 12.66 frames per second, with 79 milliseconds of latency per frame. The model and paper were released in June 2026, accepted to ECCV 2026, the European Conference on Computer Vision.
The model edits existing video rather than generating new footage from scratch. It takes a video clip and a text instruction, then applies the edit in real time as the video streams through the model. The distinction from text-to-video generators is practical: LiveEdit changes what is already in a shot, it does not create new content.
LiveEdit teaser: real time streaming video editing with text instructions
What Streaming Video Editing Means in Practice
Most AI video editing tools process an entire clip before returning results. You submit a video, wait for the model to complete a full inference pass, and receive the output as a finished file. The minimum latency is always at least the full clip duration plus processing time.
LiveEdit processes video causally, editing each chunk before the next one arrives. The model does not see the full clip in advance. It edits frame by frame as video streams through, which is what makes the 79ms per frame figure achievable. At 12.66 FPS output, the model runs at roughly half the speed of 24 FPS broadcast video, approaching the threshold where an editor sees results almost as fast as the source plays.
For a filmmaker or editor, the feedback difference is significant. Batch editing produces results in seconds to minutes depending on clip length. Streaming editing produces results continuously during the pass, enabling iterative review that conventional processing cannot support.
A Three Stage Distillation Pipeline
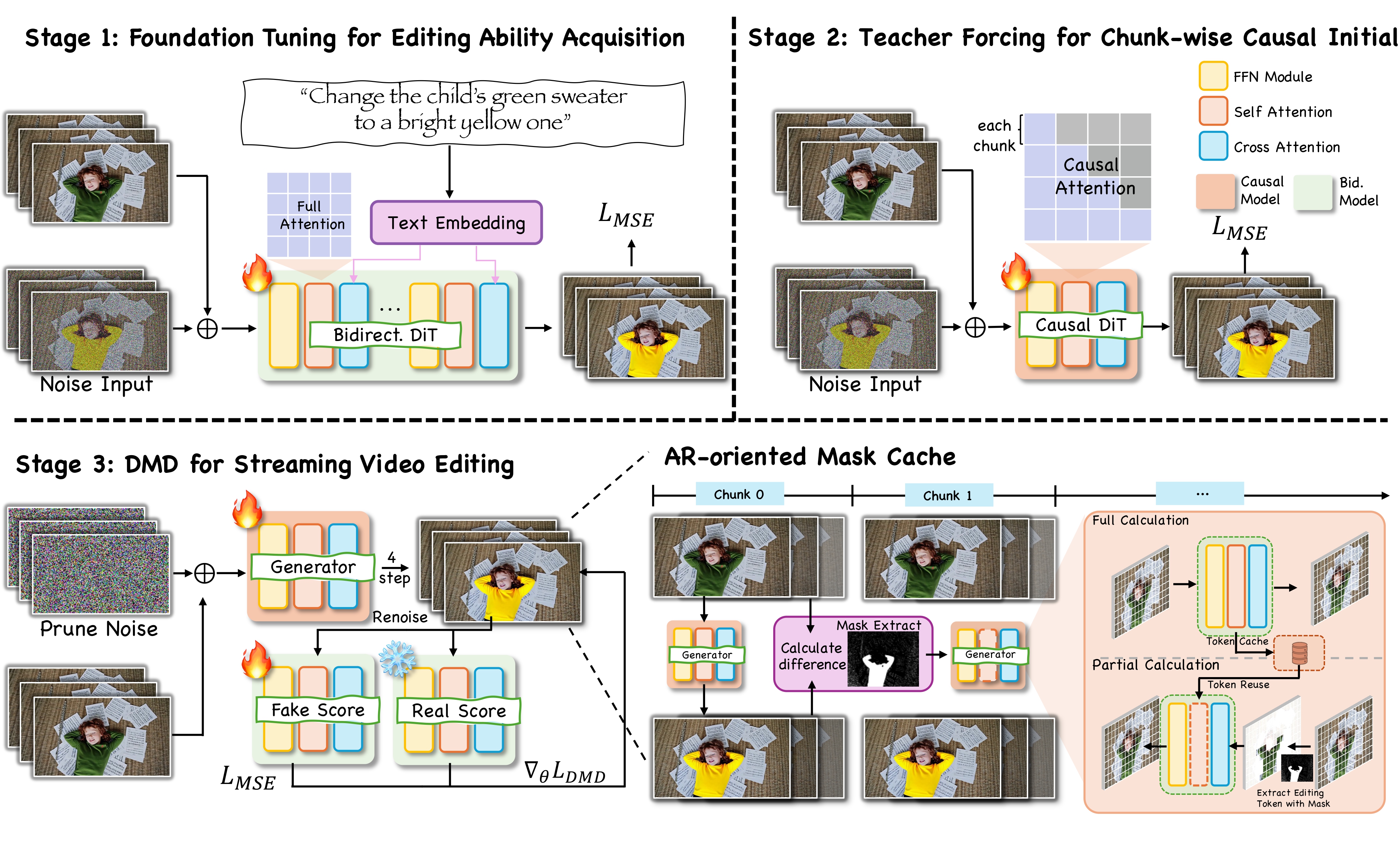
LiveEdit builds on two existing open source projects: the Wan2.1-T2V-1.3B video model as the generation backbone, and Self-Forcing, which provides the streaming autoregressive framework. Neither was designed for real time video editing in its original form. The research contribution is the distillation process that compresses the 100 step inference requirement of the original model down to 4 steps without losing edit quality.
The compression follows three stages. First, foundation tuning adapts the base model to the streaming editing task. Second, teacher forcing trains the compressed 4 step model against the 100 step teacher's outputs to preserve visual quality. Third, distribution matching distillation (DMD) finalizes the speed reduction. Each stage has a specific role, and the training code for all three ships with the GitHub repository.
The 25x reduction in inference steps is how LiveEdit achieves real time performance. The ECCV paper benchmarks it against StreamDiffusion and StreamV2V, the two most comparable existing open source streaming tools, across edit quality and latency metrics.
LiveEdit architecture, source: Wang, Zhao, Zhan, Ma, ECCV 2026
The three stage pipeline compresses 100 inference steps into 4 without retraining the base model from scratch. Foundation tuning adapts the streaming task, teacher forcing preserves output quality, and DMD applies the final speed compression. The result is a model that can be run at real time speeds on hardware that would struggle with the full 100 step version.
The training code, including a FlashAttention-2 JVP kernel used in the distillation process, is included in the repository. Teams working on similar distillation problems for other base models can use the LiveEdit codebase as a reference implementation.
The AR Oriented Mask Cache
The key architectural mechanism behind LiveEdit's streaming performance is what the paper calls the AR oriented Mask Cache. As the model processes video chunk by chunk, many spatial regions remain unchanged between consecutive frames. The Mask Cache identifies those stable regions and reuses their computed feature representations rather than recalculating them on every frame.
Without this mechanism, a naive streaming implementation would recompute all spatial regions on every frame regardless of whether the text instruction affected them. The Mask Cache restricts recomputation to only the regions the current edit instruction actually modifies, carrying cached values forward for everything else. That region level selective reuse is where the real time latency improvement comes from.
The mechanism is architecturally specific to streaming causal video editing and not a general speed technique borrowed from other AI contexts. It is designed for the particular problem of maintaining temporal consistency across chunks when only part of the frame is being changed, which is the most computationally expensive aspect of streaming video editing at quality levels comparable to full pass batch methods.
Results Gallery
Each pair below shows the source video alongside LiveEdit's edited output from the same clip. The edits are text guided and applied in real time during a streaming pass.
Fur color change: original and edited
Source
LiveEdit output: snowy white fur with blue eyes
Tree trunk recolor: original and edited
Source
LiveEdit output: silvery gray trunks, misty atmosphere
Material change: original and edited
Source
LiveEdit output: white marble with dark gray veining
The gallery demonstrates three different edit categories: a biological surface (fur), a natural environment element (bark), and an architectural material (countertop). Each edit preserves the original scene structure, camera movement, and motion while changing only the target attribute specified in the prompt.
Apache 2.0 License and How to Access
LiveEdit is released under the Apache 2.0 license, which permits commercial use, modification, and redistribution without royalty obligations. The license file was confirmed in the GitHub repository at the time of writing.
The code, pretrained checkpoints, and training scripts are available at cp-cp/LiveEdit on GitHub. The repository includes installation instructions and inference examples for running the model on existing video clips. The training code ships with the repository, making the distillation process replicable for teams working with other base models.
A community demo Space exists on HuggingFace at multimodalart/LiveEdit-Realtime. Space access may require a HuggingFace account depending on current gating status. The project page and GitHub repository do not require accounts and are the most reliable access points for the model.
Where LiveEdit Fits Among Open Source Editing Tools
The open source video editing landscape has several distinct approaches in 2026. Kiwi Edit is a motion aware video editor that processes full clips with a global attention pass, producing high consistency outputs particularly well suited to scenes with deliberate camera movement. SAMA applies instruction guided edits anchored to semantic regions identified in the first frame, preserving object identity across longer clips.
LiveEdit operates differently from both. Where Kiwi Edit and SAMA require a complete clip submission before returning results, LiveEdit streams edits in real time. That difference makes the tools complementary rather than directly competitive. Batch processing is appropriate for quality-critical work where latency is acceptable; streaming processing is appropriate for iterative review, live editing contexts, or situations where an editor needs to see changes as they apply rather than after the fact.
The 12.66 FPS output rate is also the most direct comparison point to existing streaming tools. StreamDiffusion and StreamV2V, the two ECCV benchmark comparators, operate at lower quality levels at comparable or slower speeds. LiveEdit's ECCV 2026 paper covers those benchmark comparisons in detail, with metrics across edit fidelity, temporal consistency, and latency.
Filmmakers and editors can generate AI video content for production use through the AI FILMS Studio video workspace.


Sources
arXiv: LiveEdit: Streamable Video Editing via Causal Autoregressive Models (2606.26740) GitHub: cp-cp/LiveEdit Project Page: live-edit.github.io HuggingFace: multimodalart/LiveEdit-Realtime
Continue Reading



Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Google Veo 3.1
- Kling 3.0 Pro
- LTX 2.3
- Happy Horse 1.0
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace