LongCat Video Avatar Guide 2026: 5-Minute AI Video Generation
Share this post:
LongCat Video Avatar Guide 2026: 5-Minute AI Video Generation
LongCat Video Avatar generates 5-minute+ videos with consistent character identity and stable lip-sync. The 13.6B parameter Diffusion Transformer model handles Audio-Text-to-Video (AT2V), Audio-Text-Image-to-Video (ATI2V), and video continuation in a single unified architecture.
Version 1.5 of the model, released in May 2026, swaps the audio encoder from Wav2Vec2 to Whisper-Large and cuts inference steps from 20 to 8. See the LongCat-Video-Avatar 1.5 release overview for what changed.
For broader context on LongCat's long-form capabilities, see our LongCat Video extended duration coverage.
Technical Architecture
LongCat Video Avatar uses three key mechanisms to maintain character consistency across extended durations.
Disentangled Unconditional Guidance decouples speech signals from motion. Characters behave naturally during silent segments instead of freezing or generating artifacts. The model understands that silence doesn't mean stillness.
Reference Skip Attention preserves character identity without copy-paste artifacts. Older models like InfiniteTalk produce rigid duplications. LongCat generates natural variations while maintaining recognizable identity.
Cross-Chunk Latent Stitching eliminates redundant VAE cycles. This prevents pixel degradation in long sequences. The model stitches latent representations directly, maintaining quality throughout 5-minute+ generations.
Video Examples: Character Consistency
Performance and Acting
The model maintains facial features, clothing, and body type across extended sequences.
Singing and Lip-Sync
Complex audio-to-motion synchronization including singing.
Podcast and Dialogue
Extended dialogue scenarios with natural pauses and speech patterns.
Sales and Presentation
Professional presentation scenarios with consistent character appearance.
Multi-Character Scenes
Multiple identities within the same generation maintaining individual consistency.
5-Minute Continuous Generation
Full 5-minute sequence demonstrating sustained quality and consistency.
Installation Guide
LongCat Video Avatar is open source and available for commercial use. The model weights are hosted on Hugging Face.
Requirements
- Python 3.8 or higher
- CUDA-capable GPU (12GB VRAM minimum for FP8 version)
- Git and Git LFS installed
Step 1: Clone Repository
git clone --single-branch --branch main https://github.com/meituan-longcat/LongCat-Video
cd LongCat-Video
Step 2: Install Dependencies
pip install -r requirements.txt
Step 3: Download Model Weights
Install Hugging Face CLI:
pip install huggingface-hub
Download weights to the correct directory:
huggingface-cli download meituan-longcat/LongCat-Video-Avatar --local-dir ./weights/LongCat-Video-Avatar
Step 4: Verify Installation
Check that weights downloaded correctly:
ls ./weights/LongCat-Video-Avatar
You should see model checkpoint files and configuration.
ComfyUI Integration
LongCat Video Avatar works with ComfyUI through Kijai's WanVideoWrapper.
Install WanVideoWrapper
- Open ComfyUI Custom Nodes Manager
- Search for "WanVideoWrapper"
- Install the node pack
- Restart ComfyUI
Configuration Settings
Audio CFG: Set between 3 and 5 for optimal lip synchronization. Lower values (3) produce more natural motion. Higher values (5) create tighter audio-to-video correspondence.
Overlap Frames: Set to 13-16 for standard avatar extension. Use 0 for pure Text-to-Video generation without continuation.
VRAM Optimization: The FP8 version runs on 12GB VRAM cards. The full precision version requires 24GB+.
Comparison: LongCat vs Google Veo 3.1
Google Veo 3.1 generates high-quality general video content. LongCat Video Avatar specializes in character consistency and lip-sync across extended durations.
Duration: Veo 3.1 generates up to 10 seconds. LongCat Avatar generates 5+ minutes continuously.
Character Consistency: Veo 3.1 handles short character appearances. LongCat Avatar maintains identity across minute-scale sequences.
Lip-Sync: Veo 3.1 provides basic audio sync. LongCat Avatar uses dedicated audio-to-motion models for precise synchronization.
Use Case: Veo 3.1 works for general content and short clips. LongCat Avatar suits presentations, podcasts, performances, and extended character-driven content.
For content requiring a specific character delivering 5-minute monologues or performances, LongCat's dedicated architecture provides stability that general models lack.
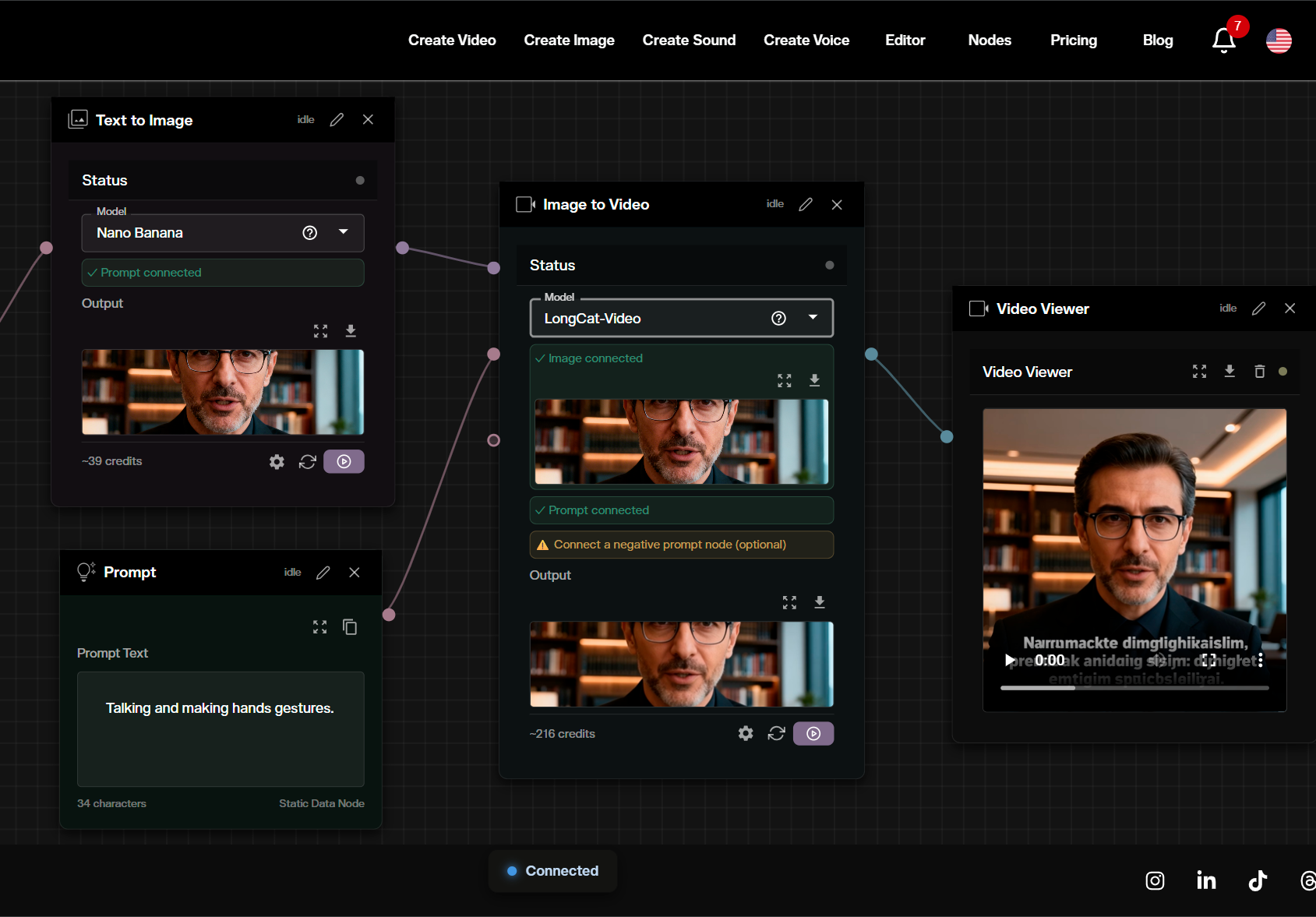
Try Professional AI Tools on AI FILMS Studio
For a hands on guide to using LongCat Video for text-to-video and image-to-video generation on the platform:


License and Commercial Use
LongCat Video Avatar is open source and available for commercial use. The code is released under a permissive license allowing commercial applications.
You can use LongCat Video Avatar in:
- Commercial video production
- Client projects
- Monetized content
- Product development
No separate commercial license required. The model weights, code, and documentation are freely available.
Optimization Settings
Audio CFG Range
Test values between 3 and 5 to find optimal lip-sync for your content. Start with 4 as a baseline.
CFG 3: More natural motion, looser audio sync CFG 4: Balanced motion and sync (recommended starting point) CFG 5: Tighter sync, more direct audio-to-motion mapping
Overlap Frames for Extensions
13-16 frames: Use for extending existing avatar videos. Provides smooth transitions between chunks. 0 frames: Use for generating new videos from text/audio only. No overlap needed.
VRAM Management
12GB Cards: Use FP8 precision version. Slightly reduced quality, significantly lower memory usage. 24GB+ Cards: Use full precision for maximum quality.
Applications
LongCat Video Avatar suits specific content types requiring extended character consistency.
Presentations and Tutorials: Create 5-minute+ instructional videos with consistent presenter appearance.
Podcast Video: Generate video for audio podcast content with host avatars.
Product Demonstrations: Show products with consistent spokesperson across extended explanations.
Educational Content: Create lecture or lesson videos with consistent instructor avatar.
Performance and Entertainment: Generate singing performances or comedy sets with character continuity.
Key Takeaways
5-Minute+ Generation: Continuous video generation exceeding typical 5-10 second limits.
13.6B Parameters: Large-scale Diffusion Transformer model for high-quality output.
Unified Architecture: Handles AT2V, ATI2V, and video continuation in single model.
Stable Lip-Sync: Dedicated audio-to-motion modeling for accurate synchronization.
Character Consistency: Maintains identity, clothing, and appearance across full duration.
Open Source: Available for commercial use without licensing fees.
ComfyUI Support: Integrates with existing workflows through WanVideoWrapper.
12GB VRAM Option: FP8 version accessible on consumer hardware.
For additional context on LongCat's broader capabilities including 15-minute generation and technical architecture, see our extended LongCat Video coverage.
Official Project Sources
Project Page: https://meigen-ai.github.io/LongCat-Video-Avatar/
GitHub Repository: https://github.com/meituan-longcat/LongCat-Video
Model Weights (Hugging Face): https://huggingface.co/meituan-longcat/LongCat-Video-Avatar
Technical Paper: arXiv:2510.22200
Continue Reading



Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Google Veo 3.1
- Kling 3.0 Pro
- LTX 2.3
- Happy Horse 1.0
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace