MisoTTS: Open Weight 8B Voice Model with Voice Cloning

Share this post:
MisoTTS: Open Weight 8B Voice Model with Voice Cloning
Miso Labs released MisoTTS on June 3, 2026, an 8 billion parameter voice generation model with weights published to HuggingFace and GitHub on the day of release. The model ships under a modified MIT license, with commercial use permitted for the vast majority of deployments without any attribution requirement.
What MisoTTS Does
MisoTTS generates speech from text, with an optional audio context input for voice cloning. Given a short reference clip, the model replicates that voice's register, pacing, and tonal character for subsequent output. It also supports voice continuation, producing audio that extends naturally from a provided recording.
Miso Labs
The voice cloning capability is based on the optional audio context input. A short reference clip of a target voice is sufficient for the model to replicate the register, pacing, and tonal character of that voice in generated output. Voice continuation extends an existing recording naturally rather than creating a separate clip with an abrupt tonal shift.
The model demonstrates audio domain flexibility without fine tuning. Switching between conversational dialogue, sports commentary, and therapeutic register requires only a change in the prompt or reference clip rather than separate model weights for each domain.
That domain flexibility distinguishes MisoTTS from single purpose voice generation tools. A model trained specifically for news narration will sound authoritative but flat in dialogue applications. A model trained specifically for conversational dialogue will sound casual in contexts that require formal register. MisoTTS's demonstrated range across four distinct domains suggests the 8 billion parameter capacity allows for genuine contextual variation rather than averaging across training examples.
The model is English only at launch. Miso Labs describes its design aim as "emotive, human sounding" output, with variation in tonal register and pacing rather than flat robotic speech. Audio domains demonstrated in the official blog include conversational dialogue, sports commentary, explanatory narration, and therapeutic register, each requiring a distinct vocal quality that the model produces without fine tuning.
Architecture and Hardware Requirements
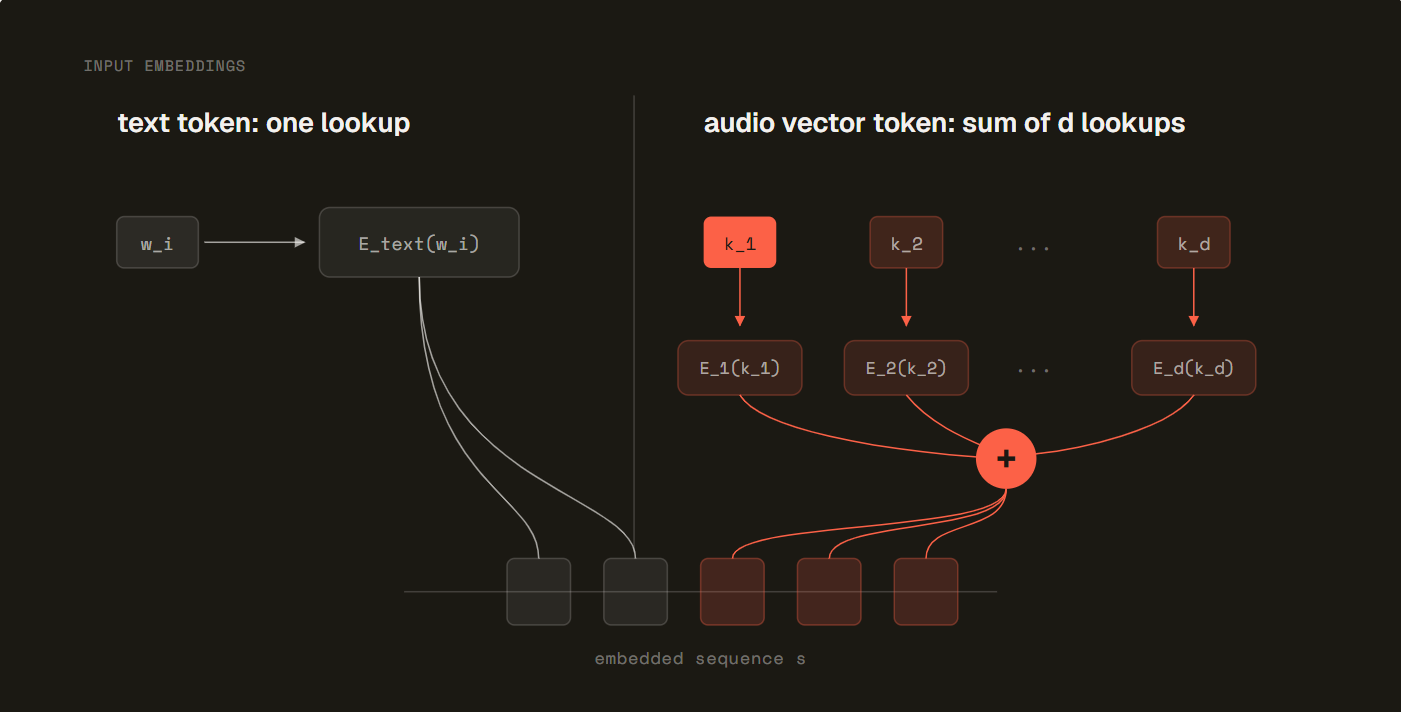
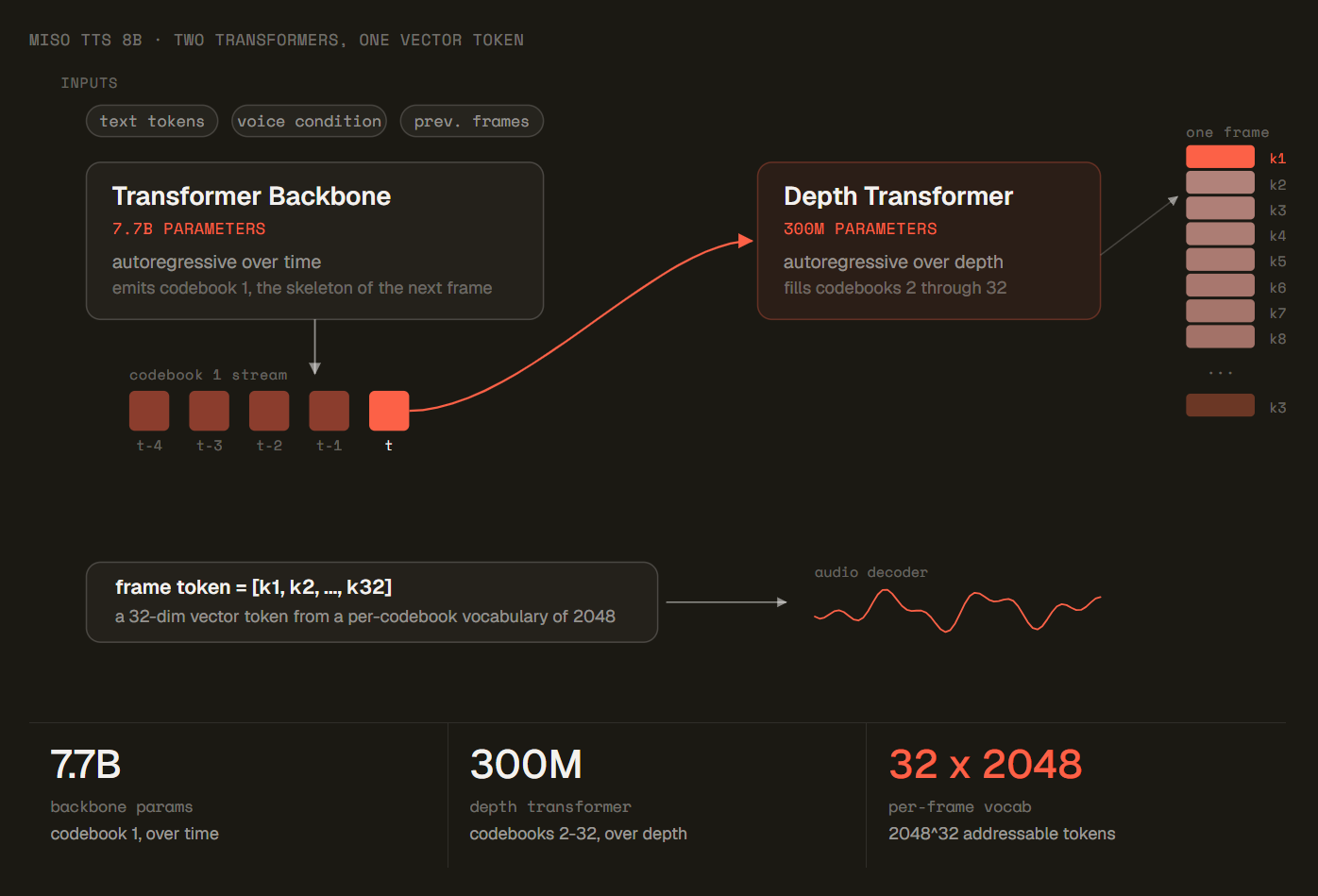
MisoTTS uses a text to dialogue residual vector quantization Transformer architecture drawing on the Sesame CSM design. The backbone is an 8 billion parameter Llama 3.2 style language model paired with a 300 million parameter audio decoder. Output passes through the Mimi audio codec across 32 codebooks, which Miso Labs states enables a wider sonic range than lower codebook approaches.
The 8 billion parameter scale is notable for a voice model. Most widely deployed TTS systems are orders of magnitude smaller. The tradeoff is hardware requirement: 32GB VRAM at full precision, or 16GB in bfloat16. An RTX 3090 or RTX 4090 can run the model locally, which puts it within reach of serious independent production setups without requiring cloud GPU infrastructure.
The 32-codebook Mimi audio codec is the component that Miso Labs points to as the source of tonal range. Higher codebook counts allow the model to represent a wider range of acoustic characteristics in its output. The tradeoff with additional codebooks is inference complexity, which is part of why the 110ms latency figure is notable for a model at this parameter count.
Miso Labs
Miso Labs reports 110ms inference latency on an NVIDIA GPU, per the official blog published June 3, 2026. Running at full precision requires approximately 32GB of VRAM. The bfloat16 checkpoint halves that requirement to approximately 16GB, suited for RTX 3090 or RTX 4090 class hardware. An API is announced as coming soon but was not available at launch.
License and Commercial Use
MisoTTS is released under a modified MIT license. Commercial use is permitted without attribution for organizations below 50 million monthly active users and $10 million in monthly revenue. Above those thresholds, attribution is required. For independent filmmakers, studios, and developers, this means the model is commercially free to use and integrate into production pipelines without licensing fees or agreements.
Weights are downloadable from HuggingFace alongside a HuggingFace Spaces demo from the multimodalart team. Inference code and setup instructions are on GitHub under the same license terms as the code: Apache 2.0.
The HuggingFace Spaces demo from the multimodalart team allows browser based testing without local installation. That demo provides a practical first test for productions evaluating whether the model's voice quality is appropriate for their use case before committing to the hardware and setup required for local deployment.
The same week, the OpenMOSS team released MOSS-Audio, an open weight audio understanding model that reasons about existing audio content: transcription, speaker identification, acoustic event detection. MisoTTS generates speech; MOSS-Audio analyzes it. The two cover opposite ends of the audio production pipeline. For live music generation, Google's Magenta RealTime 2 also released that week, running as an Audio Unit plugin inside Logic Pro and GarageBand at 200ms latency on Apple Silicon.
Released three days after MisoTTS, dots.tts from Hilab takes a different architecture to voice cloning: fully continuous latent space with no discrete token quantization, achieving a 54ms streaming latency and context aware emotion inference from the target script.
What "Emotive, Human Sounding" Means in Practice
Miso Labs' design aim for MisoTTS is "emotive, human sounding" output rather than neutral flat speech. The distinction matters for filmmaking applications where voice quality affects whether audiences accept a performance as credible.
Neutral flat speech is what early TTS systems produced. It worked for navigation prompts and form reading. It fails for character dialogue, documentary narration, and audiobook performance where emotional register is part of the content. Variation in tonal register across a sentence, natural pacing changes at clause boundaries, and subtle acoustic qualities that indicate the speaker's emotional state are all elements that make speech sound human rather than synthetic.
The specific mechanism that produces these qualities in MisoTTS is the combination of the language model backbone and the Mimi codec. The language model handles text understanding and prosody planning. The codec handles the acoustic realization. At 8 billion parameters, the language model has sufficient capacity to represent the complex relationships between text content and appropriate vocal expression.
The Modified MIT License in Detail
The modified MIT license Miso Labs chose creates a commercial use tier structure based on organizational scale. The free commercial use threshold of 50 million monthly active users and $10 million in monthly revenue is intentionally set above the scale of independent filmmakers, studios, and most production companies.
For the purposes of filmmaking production, the license is effectively MIT. A documentary filmmaker generating narration tracks, a game developer creating character voices, or a production company building an internal audio tool will operate well within the free tier. The thresholds exist to capture revenue from consumer applications deployed at scale, not production use.
The Apache 2.0 license on the inference code is separate from the model weight license. Developers building integration tools, pipeline scripts, or API wrappers around MisoTTS work under Apache 2.0 for the code layer, with the model weight license governing what they do with the model itself.
Comparing the Open Weight Voice Model Landscape
MisoTTS entered a field with several existing open weight voice generation options in June 2026. The comparison that matters for production use is not just quality but the combination of quality, latency, and licensing.
At 8 billion parameters, MisoTTS is larger than most deployed open weight TTS models. Smaller models run faster but represent less acoustic diversity. The 110ms latency at this parameter count suggests efficient inference optimization rather than a compromise on model size.
MOSS-Audio and MisoTTS together cover the full audio pipeline for filmmaking applications: generation on one end, understanding and analysis on the other. Productions that need to generate dialogue, then analyze that dialogue for timing, speaker separation, or transcription accuracy, now have open weight options for both tasks without a dependency on proprietary services.
The open weight availability of both models means production teams can combine them on local hardware or private cloud infrastructure. A team that generates character dialogue with MisoTTS, then uses MOSS-Audio to verify transcription accuracy and check timing alignment, is running a complete audio production verification loop without transmitting content to external services. For productions under NDA or with contract restrictions on sharing unreleased audio, that closed-loop workflow is the right architecture.
The Architecture in Context
MisoTTS builds on a lineage of open research in neural TTS. The text to dialogue residual vector quantization Transformer approach draws on published work from both the academic TTS community and the language model research community. The Sesame CSM reference in Miso Labs' description places the model in a design tradition that uses language model priors for prosody planning rather than treating TTS as a purely acoustic signal processing task.
The Llama 3.2 style backbone at 8 billion parameters reflects a choice to scale the language modeling component rather than the acoustic component. The 300 million parameter audio decoder handles the acoustic realization. That split, with the larger parameter count on the language understanding side, is consistent with the design goal of producing speech that reflects textual meaning rather than just phoneme sequences.
The Mimi codec was developed by Kyutai for their Mimi audio model and published as an open source component. Its use in MisoTTS reflects how open source audio research components are being combined with independently developed language model backbones to produce models that neither team could have built alone within the same development timeline.
That component reuse pattern is how the open source AI ecosystem accelerates. Kyutai developed Mimi for one purpose. Miso Labs identified it as the best available codec for their design goals and incorporated it. The result is a model with a better acoustic component than Miso Labs could have developed independently within the same timeframe, built on research that Kyutai made available to the community.
The Sesame CSM design reference is similar. The architectural approach developed at Sesame provided a foundation that Miso Labs built on rather than starting from first principles. These layers of open research building on previous open research are what make a four person team capable of releasing an 8 billion parameter voice model with competitive performance characteristics.
Local Inference for Production Pipelines
The ability to run MisoTTS locally on a single GPU is relevant for productions that need voice generation within a pipeline that handles other computationally intensive tasks. A production workflow that generates visual content, processes it, and generates synchronized audio can potentially run all components on local hardware rather than routing different tasks through different cloud services.
Local inference also means privacy. Productions working with proprietary scripts, unreleased character voices, or sensitive audio content can process everything on their own hardware without transmitting audio content to external APIs. For productions under NDA or with strict security requirements, local inference is not a convenience but a necessity.
The 16GB bfloat16 option is particularly relevant for workflows that share a GPU with other tasks. A single RTX 4090 at 24GB of VRAM can run MisoTTS in bfloat16 while retaining capacity for other lightweight inference tasks. That headroom makes MisoTTS usable in integrated production pipelines rather than requiring dedicated hardware.
Practical Filmmaking Applications
The audio domains MisoTTS demonstrates, conversational dialogue, sports commentary, explanatory narration, and therapeutic register, map onto a range of filmmaking use cases.
Documentary narration is the most straightforward application. A narrator's voice can be established from a short reference clip and used consistently across an entire production. For productions that need narration in multiple cuts or languages, the ability to generate consistent voice output without calling back a human narrator for each revision changes the post production workflow.
Character dialogue prototyping is a second application. A director developing a scene can generate rough audio for character lines using MisoTTS to evaluate pacing and timing before recording with actors. That use parallels how visual effects previsualization works: a rough version for planning purposes, not the final product.
Audiobook production is a third use case where the license terms and voice quality combine favorably. A publisher producing audiobook content from an established narrator's voice can use a short reference clip to generate consistent output across a full manuscript. The modified MIT license permits that use within the commercial thresholds without requiring a separate licensing agreement.
The model's English only limitation at launch narrows these applications to English language productions. Miso Labs has not published a timeline for additional language support, but the architecture does not preclude it. Productions working in other languages should monitor the model's development roadmap rather than building MisoTTS into pipelines that require multilingual output now.
Filmmakers working on voice production can explore AI voice and sound generation in the AI FILMS Studio voice workspace and sound workspace.


Sources
Blog post date: June 3, 2026
Project page: misolabs.ai/blog/miso-tts-8b
GitHub: MisoLabsAI/MisoTTS
HuggingFace model: MisoLabs/MisoTTS
HuggingFace demo: multimodalart/MisoTTS
License: Modified MIT. Commercial use permitted below 50M MAU / $10M MRR threshold
Continue Reading

.jpg?w=3840)

Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Gemini Omni
- Google Veo 3.1
- Kling 3.0 Pro
- Luma Ray 3.2
- LTX 2.3
- Happy Horse 1.1
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace