MOSS-Audio: Open Source Audio Understanding Model Under Apache 2.0

Share this post:
MOSS-Audio: Open Source Audio Understanding Model Under Apache 2.0
OpenMOSS published the formal technical report for MOSS-Audio on June 1, 2026, releasing it under Apache 2.0 for commercial use. The model analyzes speech, environmental sound, and music across four variants ranging from 4.6 billion to 8.6 billion parameters, with a dedicated reasoning mode that produces written explanations of its audio assessments alongside the results.
What MOSS-Audio Does
MOSS-Audio is an audio understanding model, not a generation model. It takes audio files as input and returns analysis: transcriptions with word level timestamps, speaker identification, emotion and pitch detection, environmental sound classification, music analysis, and answers to natural language questions about audio content.
The distinction matters for filmmakers. MOSS-SoundEffect v2.0 generates sound effects from text descriptions, and NAVA generates synchronized video and audio from a single prompt. MOSS-Audio does the complementary job: it tells you what is already in a piece of audio and explains why.
Architecture
MOSS-Audio couples a dedicated audio encoder with a modality adapter and a large language model. The encoder runs at 12.5 Hz temporal resolution, processing audio into tokens the language model can read.
Two innovations distinguish it from earlier audio language models. The first is DeepStack cross layer feature injection: instead of using only the final encoder output, the system selects and independently projects features from earlier and intermediate encoder layers, injecting them into the early layers of the language model. This gives the LLM richer low level acoustic context alongside the high level semantic summary. The second is time aware representation: explicit time tokens are inserted between audio frame representations at fixed intervals during pretraining, which allows the model to ground every word, sound event, or musical phrase to a specific moment in the recording.
Four Variants, Two Modes
The release includes four models: MOSS-Audio-4B-Instruct (~4.6B parameters), MOSS-Audio-4B-Thinking (~4.6B), MOSS-Audio-8B-Instruct (~8.6B), and MOSS-Audio-8B-Thinking (~8.6B). All four use the Qwen3 backbone at their respective sizes.
The Instruct variants produce direct answers. The Thinking variants generate chain of thought reasoning alongside the result, working through the analysis step by step before delivering a conclusion. For a question about what emotion is present in a dialogue recording, the Thinking mode returns the reasoning behind the answer rather than a label alone. The 8B-Thinking variant achieves the highest scores across all benchmarks.
Benchmark Performance
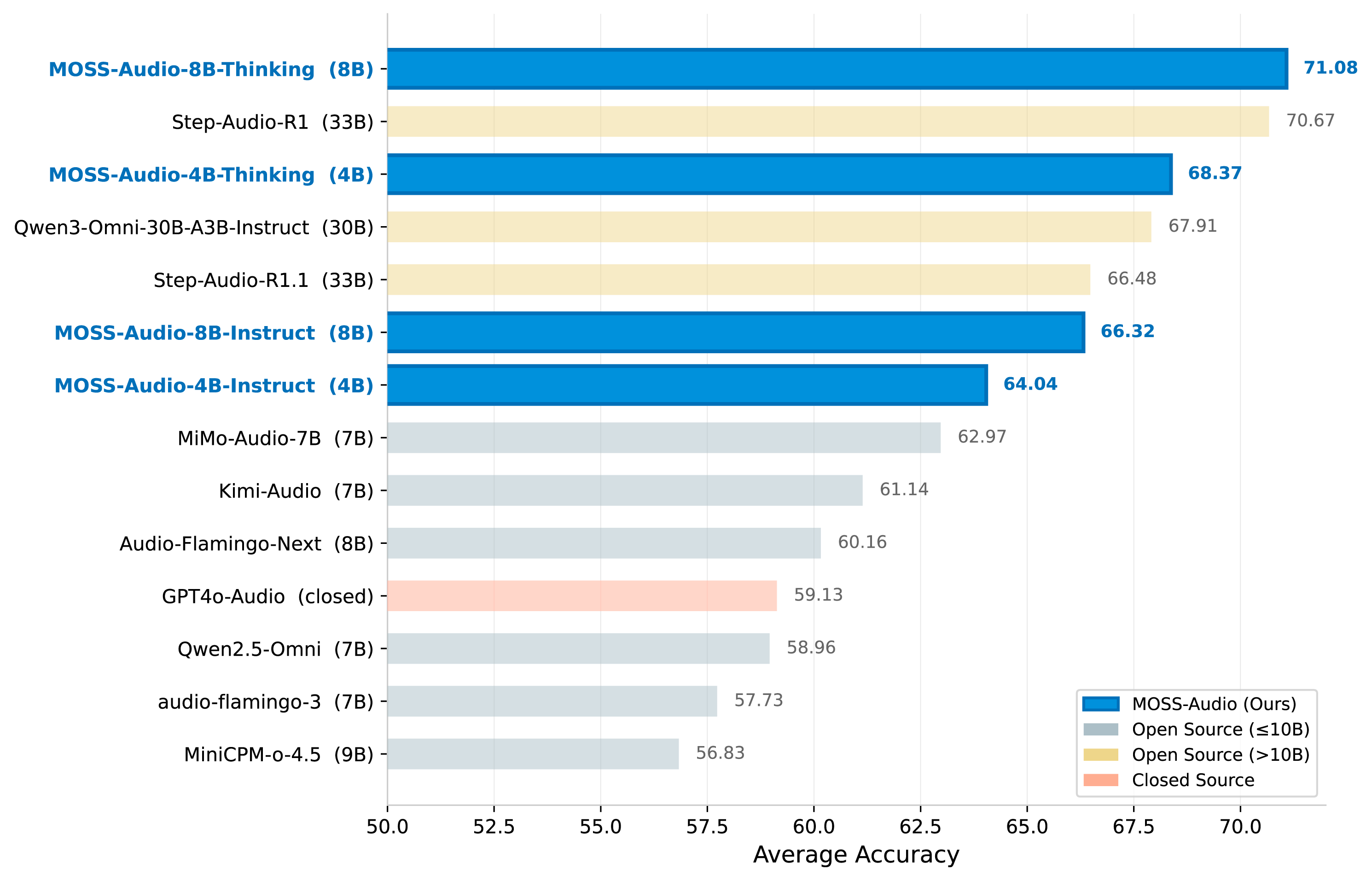
On general audio understanding, MOSS-Audio-8B-Thinking scores 71.08 on average across four benchmarks: MMAU (77.33), MMAU-Pro (64.92), MMAR (66.53), and MMSU (75.52). These results represent a meaningful lead over publicly available alternatives at comparable scale.
On timestamp aligned speech recognition, lower alignment score means better performance. MOSS-Audio-8B-Instruct scores 35.77 on AISHELL-1 and 131.61 on LibriSpeech. Qwen3-Omni scores 833.66 and 646.95 on the same benchmarks. Gemini-3.1-Pro scores 708.24 and 871.19. The gap across all tested models is substantial.
Speech Captioning
On the speech captioning task, MOSS-Audio-8B-Instruct achieves an average score of 3.7252 and leads on 11 of 13 evaluated dimensions including gender, accent, pitch, volume, and emotion.
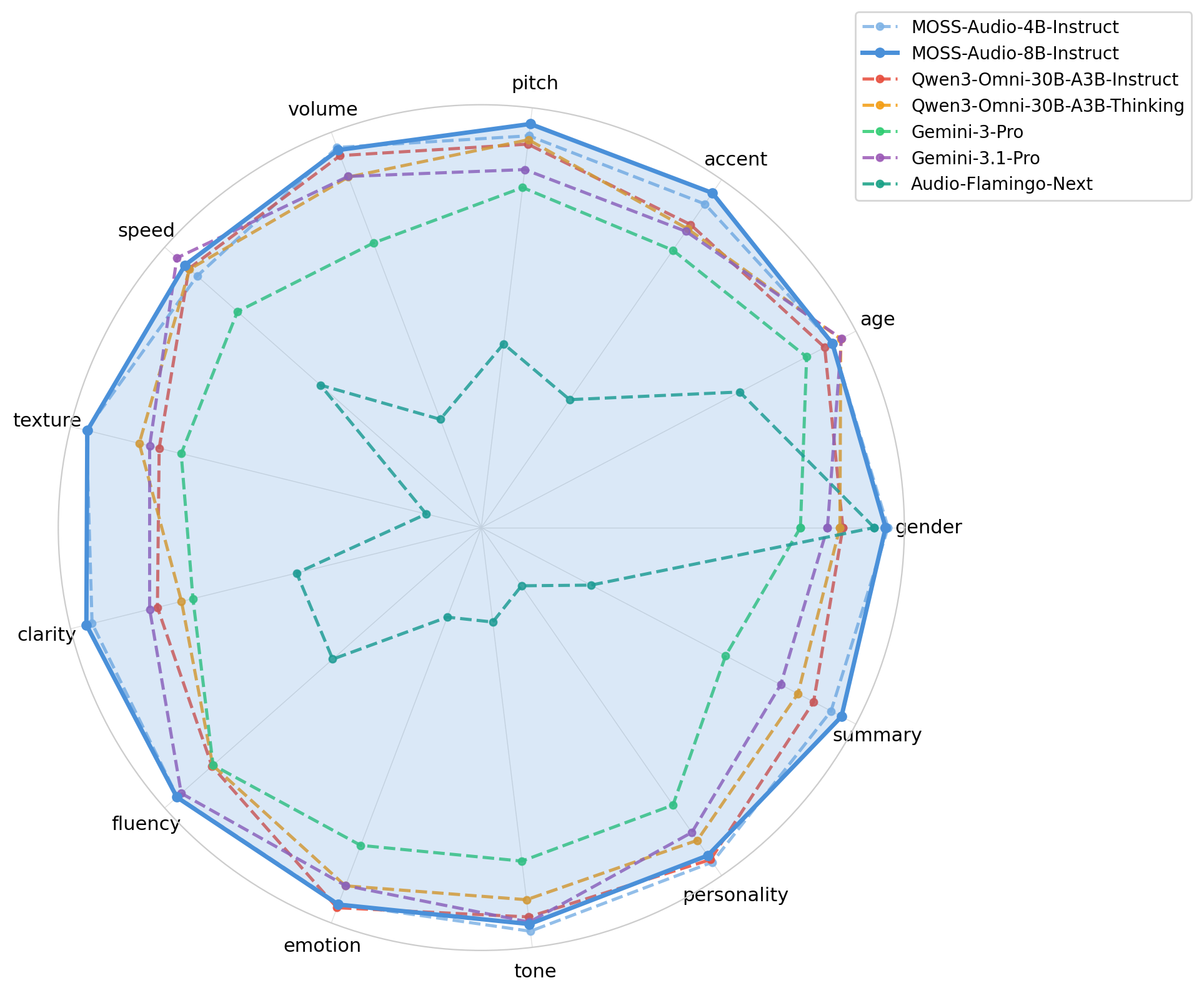
The overall ASR character error rate for 8B-Instruct is 11.30, the lowest among all tested models. The evaluation set deliberately covers non standard speech: health conditions, code switching, dialects, singing, and non speech audio scenarios all appear in the benchmark.
What Filmmakers Can Do With It
Automated dialogue transcription with precise timestamps removes a manual step from post production editorial prep. The word level alignment means sync points can be located exactly rather than approximated. On the sound design side, the model can analyze and tag production sound libraries at scale, returning descriptions accurate enough for search and retrieval across environmental sound, music, and voice recordings.
The Thinking variants add a layer that pure generation tools do not offer. Models like JavisDiT++ create audio content from instructions. MOSS-Audio's reasoning mode explains what is in existing audio and articulates why specific elements are present, making it useful for sound supervision and reference analysis rather than generation. A music supervisor analyzing why a reference cue creates tension now has a model that can break down the pitch, tempo, instrument composition, and harmonic elements and explain their combined effect.
Stable Audio 3 generates original music from text. MOSS-Audio is the corresponding understanding layer: it reads existing audio with the same depth that generation models apply to writing it.
For voice and speech specifically, MisoTTS released the same week as an 8 billion parameter open weight voice model under a modified MIT license, covering speech generation from text and one shot voice cloning from a short audio sample. The OpenMOSS team followed in June 2026 with MOSS-TTS Local Transformer v1.5, a 5B parameter voice cloning model that generates 48 kHz stereo speech across 31 languages with explicit dialogue timing control under Apache 2.0. For original music generation rather than speech or audio analysis, Google's Magenta RealTime 2 also released that week under CC-BY-4.0, running as an Audio Unit plugin inside any AU compatible DAW at 200ms control latency.
The model runs locally with Python 3.12, FFmpeg 7, and CUDA 12.8. Optional FlashAttention 2 support is available for compatible hardware. Weights for all four variants are available via HuggingFace. For filmmakers working on audio production, the sound workspace and music workspace in AI FILMS Studio cover the generation side of the workflow.


Sources
GitHub: OpenMOSS/MOSS-Audio
HuggingFace (4B-Instruct): OpenMOSS-Team/MOSS-Audio-4B-Instruct
HuggingFace (8B-Instruct): OpenMOSS-Team/MOSS-Audio-8B-Instruct
HuggingFace (8B-Thinking): OpenMOSS-Team/MOSS-Audio-8B-Thinking
arXiv: MOSS-Audio Technical Report
License: Apache 2.0 (commercial use permitted)
Continue Reading



Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Gemini Omni
- Google Veo 3.1
- Kling 3.0 Pro
- Luma Ray 3.2
- LTX 2.3
- Happy Horse 1.1
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace