dots.tts: Fully Continuous Voice Cloning at 54ms Streaming Latency

Share this post:
dots.tts: Fully Continuous Voice Cloning at 54ms Streaming Latency
Hilab, the research division of Chinese social platform RedNote, released dots.tts on June 9, 2026. The model clones any voice from a short reference clip and synthesizes new speech at a first token streaming latency of 54ms. It is released under Apache 2.0, permitting commercial use.
The name "dots" reflects the model's core design: it operates entirely in continuous latent space rather than converting audio to discrete tokens at any stage. That single architectural choice is the basis for both the latency advantage and the voice identity fidelity.
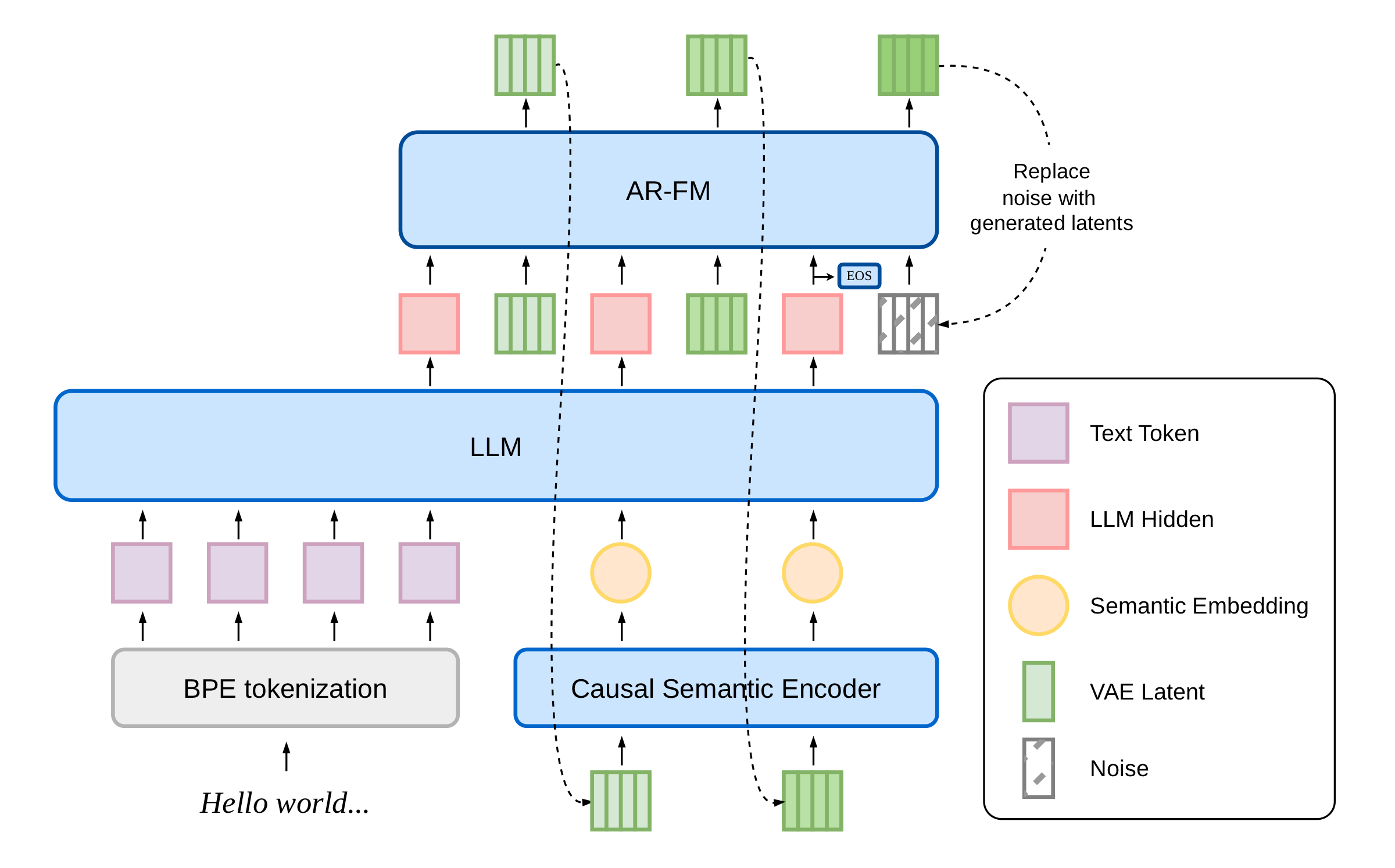
Fully Continuous Architecture
Most TTS models built on language model architectures convert audio to discrete tokens through a codec or quantizer before generation. That tokenization step introduces artifacts and compresses the acoustic detail that defines a speaker's voice. Voice cloning across a discrete token boundary tends to preserve coarse speaker characteristics while losing fine grained qualities: breath patterns, resonance, and naturalistic timing.
dots.tts skips quantization entirely. Both the reference voice and the synthesized output exist as continuous latent representations throughout the pipeline. The model matches a reference speaker's characteristics directly in continuous space, preserving acoustic detail that a tokenization step would discard.
The 54ms first token latency follows from the same design. Discrete token models typically complete full acoustic token generation before decoding begins. A fully continuous streaming pipeline outputs audio as the latent representation is built, without waiting for a complete token sequence.
Monolingual and Cross Lingual Voice Cloning
The monolingual demo below uses a reference clip from the SeedTTS English evaluation set. dots.tts clones the speaker's voice and generates a new utterance in English with different content.
Reference
"The CrossLand acquisition gave Washington Mutual a toe hold entry into Oregon via Portland."
Result
"In many cases, such as France, no distinct regional substructures have been employed."
Cross lingual cloning transfers the speaker's voice to speech in a different language. The voice identity, accent color, and prosodic characteristics from the reference carry over while the phoneme set switches to the target language. For filmmakers, this is the mechanism behind localized dubbing that preserves a character's vocal identity across language versions.
Context Aware Expressive Voice Cloning
The expressiveness section of the demo is labeled "Cue Inferred from Target Text". No emotion tag, style label, or prompt annotation is supplied to the model. dots.tts reads the semantic content of the target script and infers the appropriate emotional delivery on its own.
Reference (neutral)
"The fact we were able to complete the construction work on schedule is a testament to everyone's hard work."
Result (emotion inferred)
"How could you possibly believe such an obvious lie?" Daniel questioned incredulously. "The story doesn't even make logical sense if you think about it for more than five seconds!"
The reference clip is a neutral declarative sentence. The target text is dialogue loaded with incredulity and frustration. The output matches the emotional register of the text without any manual annotation. For filmmakers generating dialogue with a fixed character voice, this removes the need to author emotion tags for every line of script.
Benchmark Results
dots.tts was evaluated on two standard benchmarks for voice cloning quality: the Emergent TTS evaluation set and the SeedTTS evaluation set. Both measure speaker similarity and naturalness against competing models.
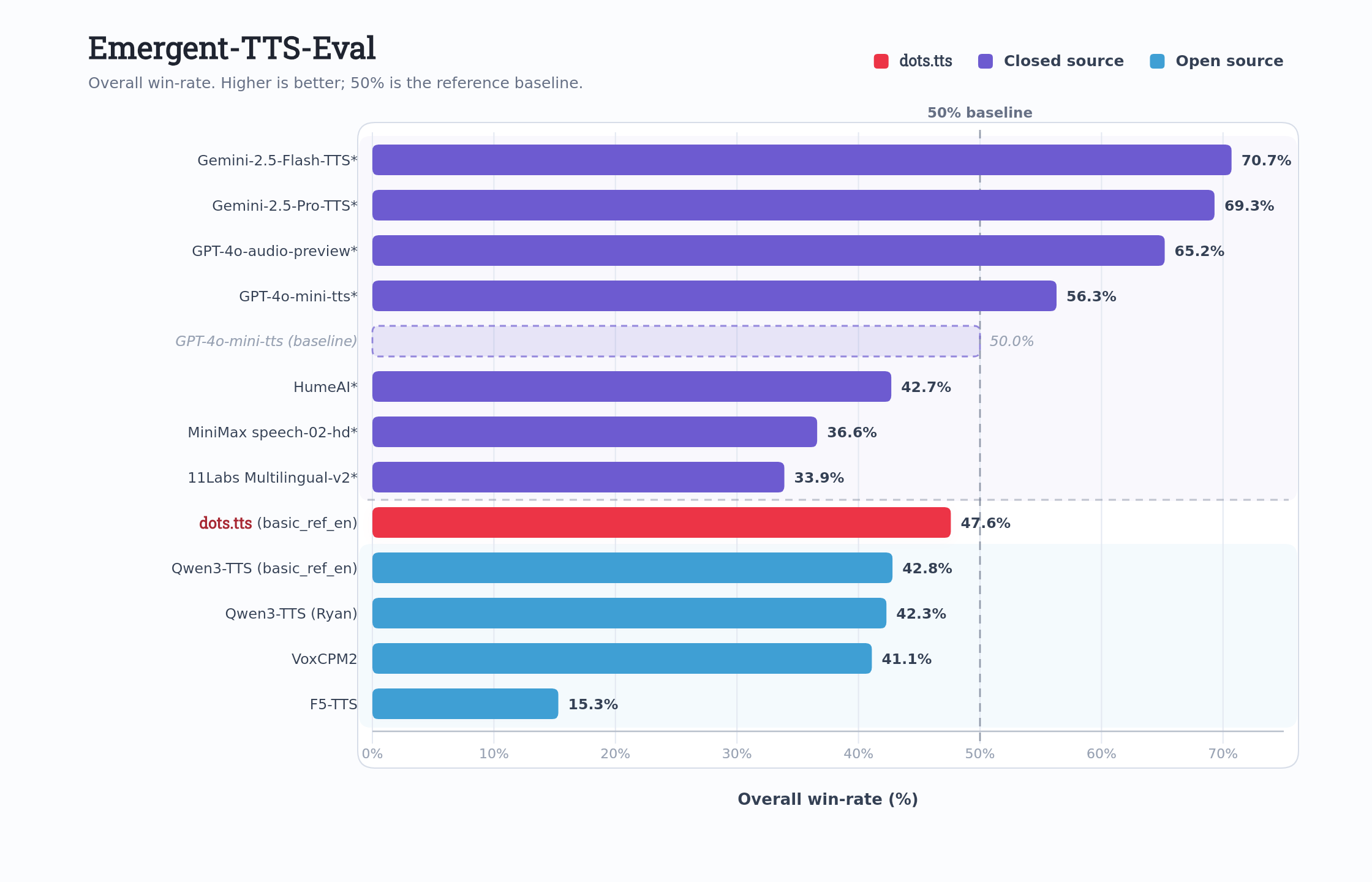
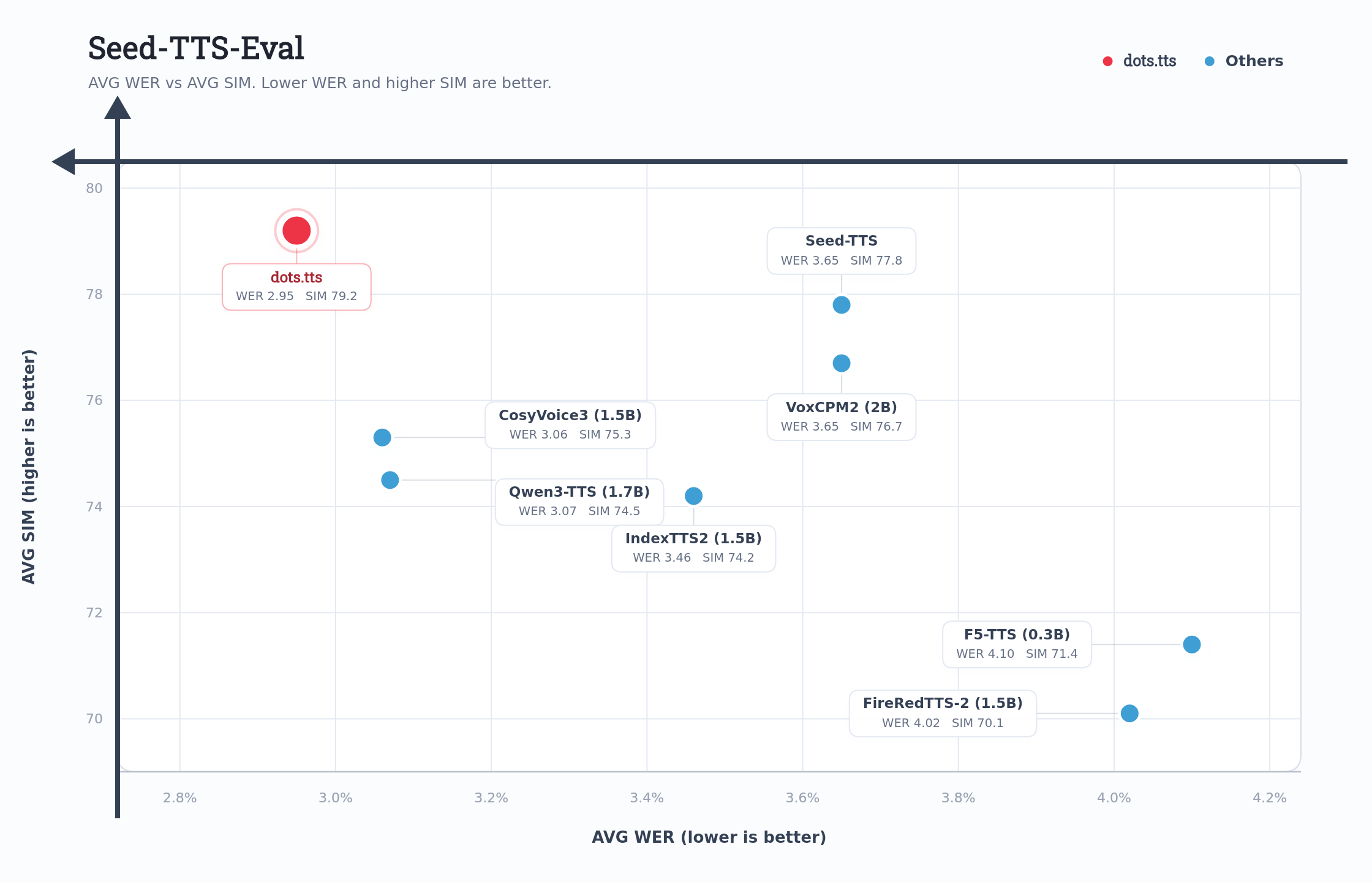
The paper reports state of the art results on both evaluation sets across speaker similarity and naturalness metrics.
Streaming Latency and Production Pipelines
The 54ms first token latency places dots.tts in the range required for real time interactive applications. Conversational systems typically require under 200ms end to end response time; at 54ms, dots.tts leaves substantial headroom for network and post processing overhead. For production pipelines rather than real time applications, 54ms matters for a different reason: it determines how tightly dots.tts output can be coupled to a downstream lip sync model.
LongCat-Video-Avatar 1.5 takes audio as input and generates lip synced video. The lower the voice generation latency, the tighter the pipeline from script line to animated character output. For a direct comparison with another open source voice cloning model, MisoTTS 8B targets the same voice cloning use case at a different architectural point. For teams prioritizing production audio quality and dialogue timing control over streaming latency, MOSS-TTS Local Transformer v1.5 from OpenMOSS generates 48 kHz stereo speech in 31 languages with explicit pause syntax under Apache 2.0. For productions requiring speech, sound effects, and music generated together in one pass from a video input, Foley-Omni handles the full audio layer simultaneously rather than generating voice separately.
Voice generation workflows are available in the AI FILMS Studio voice workspace.


Sources
Demo Page: rednote-hilab.github.io/dots.tts-demo
GitHub: rednote-hilab/dots.tts
HuggingFace: rednote-hilab/dots.tts
Continue Reading



Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Gemini Omni
- Google Veo 3.1
- Kling 3.0 Pro
- Luma Ray 3.2
- LTX 2.3
- Happy Horse 1.1
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace