Pixal3D: Open Source 3D Asset Generation from a Single Image (MIT)

Share this post:
Pixal3D: Open Source 3D Asset Generation from a Single Image (MIT)
Tencent ARC Lab, in collaboration with Tsinghua University and Victoria University of Wellington, released Pixal3D under the MIT license in May 2026. The model generates high fidelity 3D assets from a single image, producing detailed geometry and PBR (Physically Based Rendering) textures in one pipeline. The paper was accepted to SIGGRAPH 2026, the principal peer reviewed venue for computer graphics research.
The Problem It Solves
Existing image-to-3D models generate assets in a canonical pose, introducing an ambiguity: the model must infer spatial structure from image pixels without a direct link between them. Pixal3D's authors describe this as "an implicit 2D-3D correspondence issue" that reduces fidelity in existing approaches.
Pixal3D generates 3D directly in the coordinate space of the input image rather than a canonical one. That alignment removes the ambiguity by preserving the spatial relationship between input pixels and output geometry throughout the generation process.
How It Works
The model uses three core components. A Pixel Aligned Structured Latent Representation compresses the 3D structure into a learnable representation aligned with the input image. An Image Back Projection Conditioner lifts multiscale image features from 2D into a 3D feature volume, giving the model unambiguous spatial context. A two stage generative process then produces the output: coarse structure first, detailed latent representation second.
The result is a 3D mesh in GLB format, a standard production format compatible with Blender, Unreal Engine, and most professional 3D pipelines. PBR textures are output alongside the geometry, removing the need for a separate texturing step.
Example Outputs
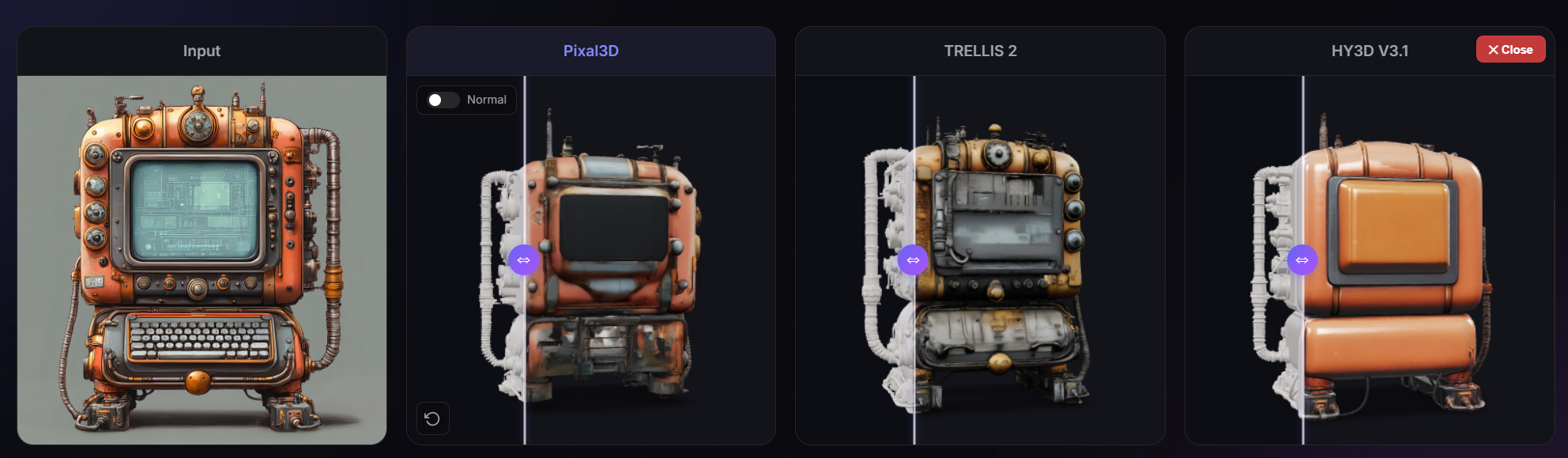
Pixal3D was benchmarked against TRELLIS 2 and HY3D V3.1, two established 3D generation baselines. The paper characterizes its output quality as approaching what reconstruction from multiple camera angles would produce, a significant bar for a single image input model.
The model also supports input from multiple views when additional reference images are available: the Image Back Projection Conditioner aggregates feature volumes from each view, improving accuracy for complex assets. A scene synthesis pipeline extends the single asset workflow to modular, object separated 3D scenes.
Two Resolution Modes
Pixal3D runs in two configurations based on available VRAM. The standard mode operates at resolution 1536 for the highest output fidelity. A low VRAM mode runs at resolution 1024, making it accessible on consumer grade hardware. Both modes produce GLB output compatible with the same production pipeline.
What It Means for VFX and Filmmakers
PBR texture output is the practical differentiator from most open source 3D generation models. Geometry only output requires a separate texturing stage before assets are usable in production. Pixal3D delivers both in a single inference pass, compressing the pipeline from concept image to production ready 3D asset.
Acceptance to SIGGRAPH 2026 gives the method peer reviewed credibility, which matters for studios evaluating open source 3D tools for professional workflows. The MIT license removes licensing risk for commercial productions.
For character design, prop modeling, and set dressing, a single image input means a reference photo or concept art can become a 3D asset without a full modeling session. The approach complements 3DreamBooth for 3D subject driven video generation, which focuses on consistency across frames rather than single asset output fidelity. For teams building 3D to video pipelines, VideoFrom3D provides the downstream step that converts generated 3D assets into animated video sequences. Input reference images can be generated through AI FILMS Studio's image workspace.


Sources
arXiv: Pixal3D: Pixel-Aligned 3D Generation from Images
GitHub: TencentARC/Pixal3D
HuggingFace: TencentARC/Pixal3D
Project Page: ldyang694.github.io/projects/pixal3d/
Continue Reading
.jpg?w=3840)


Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3
- OpenAI Sora 2
- Kling 3.0
- Kling O1
- Google Veo 3.1
- LTX 2.3
- Kling O1
- Hailuo AI
- Luma Ray
- Kling 3.0 Motion
- Topaz Upscaler
- InfiniteTalk Face Swap
Image & Edit
- AI Character
- AI Actor
- Art Generator
- Text to Image
- Image to Image
- Draw to Edit
- Image Training
- Remove Background
- Image Enhancer
- MidJourney 8.0
- OpenAI GPT Image 2.0
- Kling Image 3.0
- NanoBanana Pro
- Minimax Image
- NanoBanana 2
- Kling Omni 3
- FLUX 2
- WAN 2.6
- Z-Image
- SeedEdit 3.0
- GLM-Image
- Omnigen 2
- Seedream 4.5
- Background Erase Network 2 (BEN2)