ACE-Step 1.5: Local Music Generation That Outperforms Suno v5 on Benchmark Evaluations

Share this post:
ACE-Step 1.5: Local Music Generation That Outperforms Suno v5 on Benchmark Evaluations
ACE-Step 1.5, developed by ACE Studio and StepFun, scores 8.09 on the SongEval benchmark and outperforms Suno v5, according to arXiv paper 2602.00744. The model generates a full song in under 2 seconds on an NVIDIA A100 GPU, runs on consumer hardware with less than 4GB of VRAM, and is released under an MIT license with downloadable weights on HuggingFace.
Suno Pro costs $24 per month. Udio costs $30 per month. ACE-Step 1.5 is free.
Nine Ways to Use It
The model covers nine distinct generation and editing modes. The three foundation modes are Text2Music (original song from a text prompt with optional lyrics), Lyric2Vocal (LoRA fine tuned vocal synthesis), and Text2Samples (short audio sample generation). The three editing modes are Variations, Repaint (region level regeneration of an existing track), and Edit (Flow-Edit prompt guided audio editing, added in v0.1.8). Three specialized ControlNet and LoRA variants round out the application map: RapMachine, StemGen (stem isolation and generation), and Singing2Accom (generate a full backing arrangement from a vocal track).
For film production, the most directly useful modes are Singing2Accom for turning a scratch vocal into a scored backing track, StemGen for isolating or replacing individual instruments, Repaint for editing a specific section of a cue without regenerating the full track, and Text2Music for original score generation from scene descriptions.
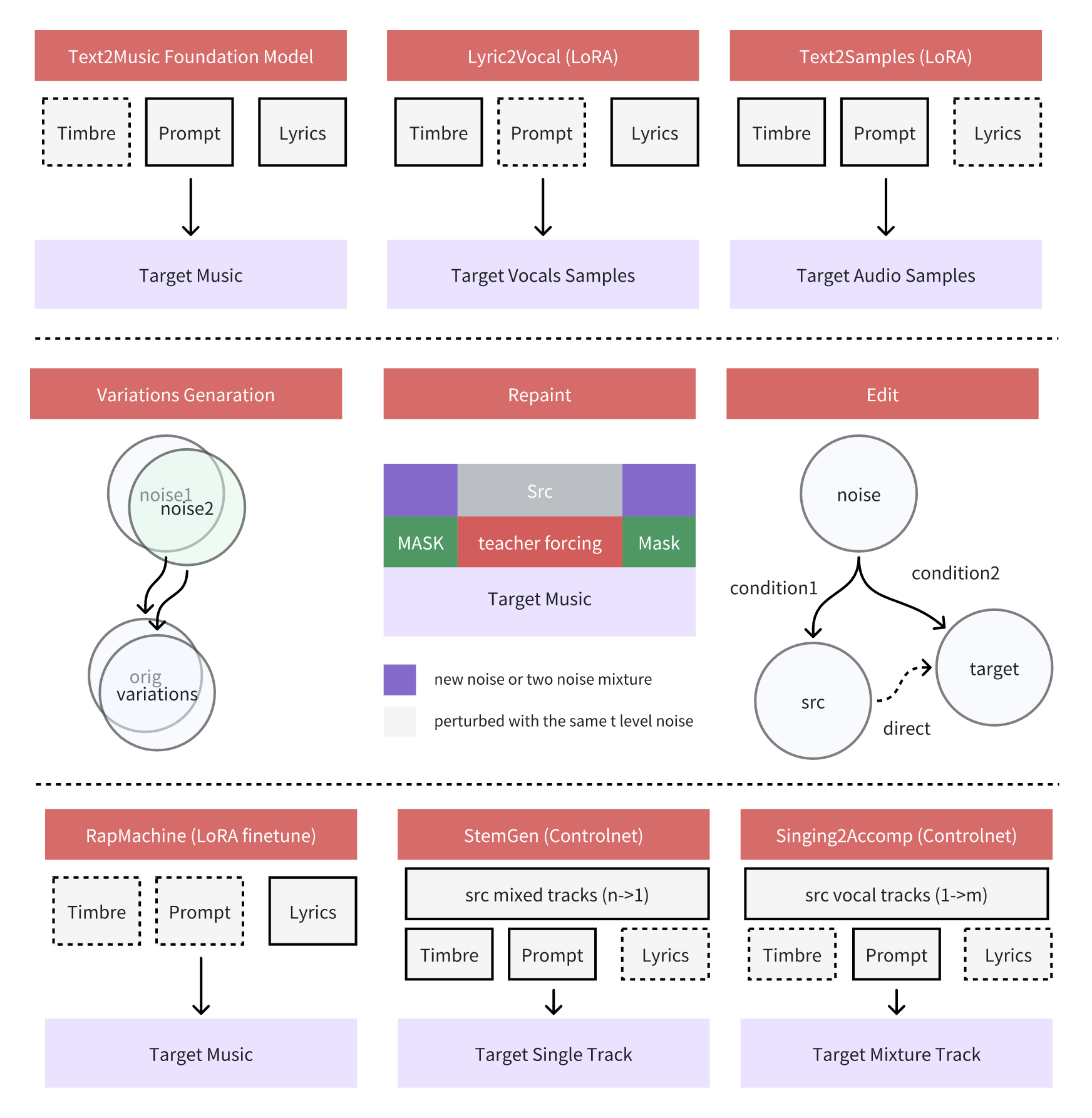
ACE-Step application modes. ACE Studio / StepFun.
The v0.1.8 update (May 18, 2026) added Flow-Edit, a prompt guided editing redesign on top of the remix workflow, and Retake variation generation, which regenerates a specific section with a variance parameter from 0.0 to 1.0.
The Singing2Accom and StemGen modes address a workflow that generic text to music models cannot. Singing2Accom converts a scratch vocal track into a complete orchestrated backing arrangement, useful when a director has hummed a reference cue or recorded a placeholder performance. StemGen can isolate or replace individual instruments in a mixed cue, enabling targeted changes without a full regeneration pass.
Architecture: Language Model as Planner, Diffusion Transformer as Generator
ACE-Step 1.5 uses a hybrid architecture that pairs a Language Model with a Diffusion Transformer. Per the paper abstract, the LM "functions as an omni-capable planner" that handles musical structure, lyric alignment across 50+ languages, and style conditioning. The Diffusion Transformer then generates the actual audio from the LM's plan.
Alignment is achieved through intrinsic reinforcement learning, using the model's own internal signals as reward feedback rather than external evaluation models. On the audio encoding side, a Deep Compression AutoEncoder compresses 44.1kHz stereo audio at 8× compression for efficient latent space generation, with MERT and m-Hubert representations providing musical understanding during training.
The hybrid architecture's speed advantage over pure language model approaches comes from the division of labor. A pure LLM generates music token by token, requiring inference steps proportional to the number of audio tokens in the output. ACE-Step 1.5's LM handles structural planning at a higher level, producing a compact plan that the DiT renders in far fewer steps.
The 8x compression ratio of the Deep Compression AutoEncoder is what makes this efficiency concrete. The DiT operates on a latent space 8 times smaller than the raw audio, without losing the musical detail that MERT and m-Hubert representations contribute during training. That combination is what makes A100 generation of a full song possible in under 2 seconds.
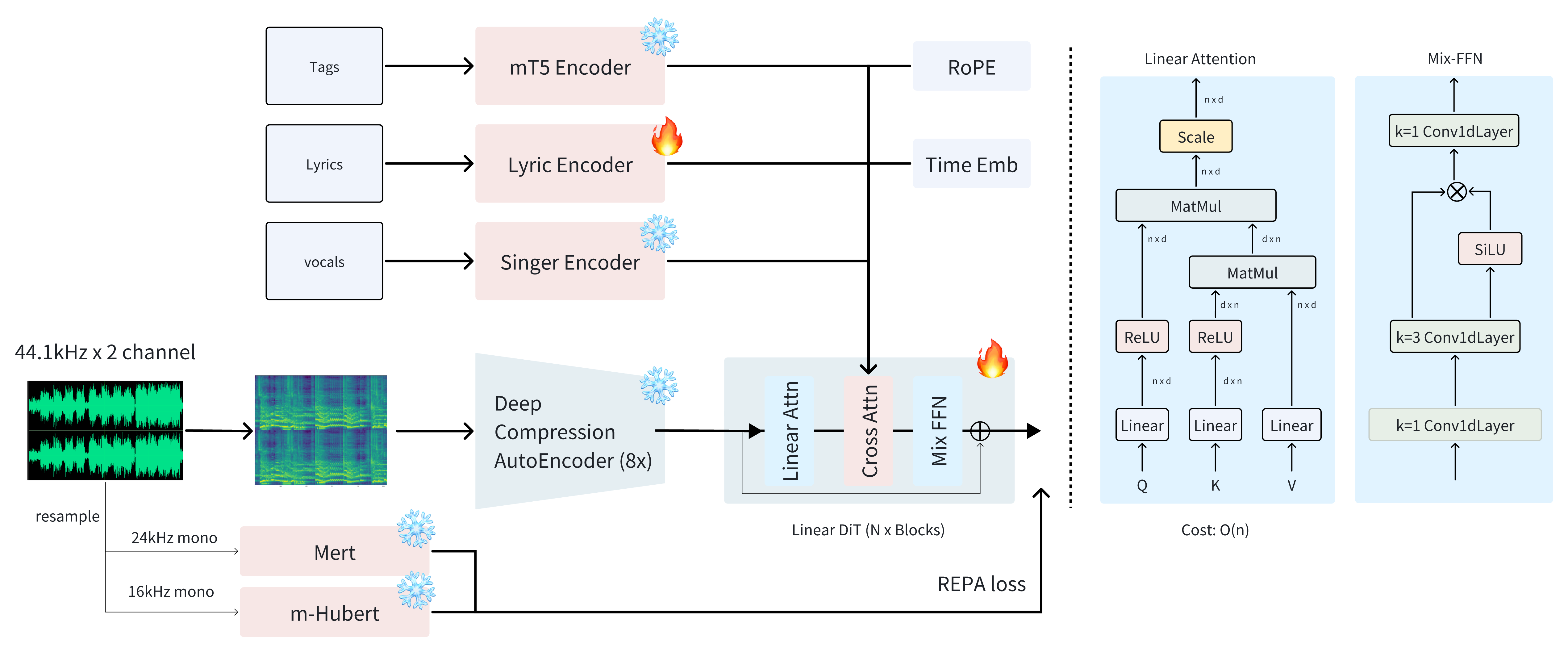
ACE-Step model architecture. ACE Studio / StepFun.
Performance Against Commercial Music AI
On SongEval, the authors report a score of 8.09, outperforming Suno v5. Additional benchmark scores from arXiv 2602.00744: AudioBox 7.42, Style Alignment 6.47, Lyric Alignment 8.35. The developers write: "On common evaluation metrics (SongEval & AudioBox), it beats SUNO and other commercial music models."
Generation speed is the other headline claim. The model produces a full song in under 2 seconds on an NVIDIA A100 and under 10 seconds on a GeForce RTX 3090. The authors report 100× faster generation than traditional pure language model architectures, and 15× faster than LLM based music baselines for compositions up to 4 minutes.
The SongEval Score in Context
SongEval measures music generation quality across multiple dimensions relevant to production use, including melodic coherence, harmonic progression accuracy, lyric alignment to the musical structure, audio fidelity, and stylistic consistency with the text prompt. A score of 8.09 means ACE-Step 1.5 performs above Suno v5 on these combined dimensions, not on any single isolated metric.
The comparison is meaningful because Suno v5 is the current commercial benchmark that independent users compare open source models against. A model that matches or exceeds it on a multi-dimensional evaluation framework provides a concrete basis for substitution in production workflows where budget, provenance, or local execution requirements make a subscription service impractical.
The AudioBox score of 7.42 and the Lyric Alignment score of 8.35 are equally relevant for film work. AudioBox measures overall audio perceptual quality. Lyric Alignment measures how precisely the generated vocals match the provided lyrics at the phoneme and syllable level. High Lyric Alignment means a generated vocal track can be used as a scratch guide with confidence that the lyrics will be legible to a music supervisor or director reviewing the cut.
The 100× speed figure compared to pure LLM baselines is relevant context for these benchmark results. Prior open source models that reached comparable quality scores required significantly more computation per song, limiting them to asynchronous rendering workflows rather than iterative sessions. ACE-Step 1.5 combines the quality level with a generation time that fits real revision cycles during picture lock.
Multi-Language Lyric Support
The mT5 encoder that handles lyric processing in ACE-Step 1.5 was trained on text across 50+ languages. That breadth means the Lyric2Vocal mode can synthesize vocal performances in languages where professional AI voice tools typically have limited coverage. For international co-productions or projects targeting non-English markets, this range removes a constraint that commercial music AI tools often impose.
The quality of lyric alignment varies across languages. The benchmark scores reported for English and Chinese are the highest quality reference points. Languages with less representation in the mT5 training data may produce less precise phoneme timing. For production use in non-English languages, test output alignment to lyrics before committing to a workflow that depends on tight synchronization.
Production teams combining ACE-Step 1.5 with Magenta RealTime 2 for live DAW accompaniment cover both generation modes from open source models under commercially permissive licenses. ACE-Step 1.5 handles full composition in under 2 seconds for pre-scored cues. Magenta RealTime 2 handles live accompaniment inside Logic Pro at 200ms latency for scoring sessions.
Both run locally with no cloud dependency. Productions working under NDA with footage that cannot leave the facility can use the full scoring workflow without uploading audio or video to an external service.
Film Production Applications
A film score generated from a text description of a scene, specifying tempo, instrumentation, and mood, can be produced in seconds locally without a subscription. The Singing2Accom mode takes a vocal track and generates a full backing arrangement from it. StemGen can isolate or regenerate individual instruments from a mixed cue, useful for creating variations on a licensed track.
The v0.1.8 Flow-Edit feature brings audio editing closer to how video editors work with footage. You describe what you want changed in a section using a text prompt rather than regenerating the full track. The Retake feature provides variance controlled regeneration for specific segments, the same pattern that exists in image generation workflows applied to audio.
The HuggingFace model card states the model was trained on legally compliant datasets including licensed music and royalty free content. For commercial productions, that provenance statement is meaningful. It reduces downstream copyright exposure in a way that models with undisclosed training data sources cannot. The MIT license permits use in commercial production pipelines without restriction.
The AI FILMS Studio music workspace provides access to AI music generation tools for film and video production. For other open source models in the audio space, see Magenta RealTime 2 and Stable Audio 3. The Suno tutorial covers a commercial alternative; ACE-Step 1.5 offers a locally runnable option with a verifiable benchmark comparison against Suno v5.
Getting Started
ACE-Step 1.5 requires Python 3.11 or 3.12. Installation uses the uv package manager: clone the GitHub repository, run uv sync, then launch the web UI with uv run acestep or the REST API with acestep-api. The model runs on NVIDIA CUDA, AMD ROCm, Intel XPU, and Apple CPU.
| VRAM | Recommended variant |
|---|---|
| 6GB or less | 2B turbo with INT8 quantization |
| 6–8GB | 2B turbo + 0.6B LM |
| 8–16GB | 2B turbo/sft + 0.6B or 1.7B LM |
| 20GB and above | XL 4B DiT without offload |
Four model variants are downloadable from HuggingFace: acestep-v15-base, acestep-v15-sft, and acestep-v15-turbo. The XL 4B DiT series was added April 3, 2026. Weights are available at ACE-Step/Ace-Step1.5 on HuggingFace.
Try It Live
The embedded demo below runs the full ACE-Step 1.5 model. Enter a genre description or mood, add optional lyrics, and generate. Works on all browsers.
The table below shows sample prompts from the General Songs section of the official project page. To hear the pre-generated audio examples, visit ace-step.github.io directly. The sample files use a format that requires Chrome or Firefox.
| Prompt | Section |
|---|---|
| electronic, rock, pop | General Songs |
| funk, pop, soul, melodic | General Songs |
| background music for parties, radio broadcasts, streaming platforms, female voice | General Songs |
| surf music | General Songs |
The project page includes additional demo sections for Instrumentals, Cover Generation, Repainting, Retake variation, Flow-Edit audio editing, Multi-language lyrics, RapMachine, and Lyric-to-Vocal conversion.
Music produced by ACE-Step 1.5 can serve as audio input for dance video generation. Alibaba's Wan-Dancer-14B generates dance video from a music audio track at minute scale, supporting five dance styles including Chinese Classical Dance, K-pop, Street, Tap, and Latin, with controls for dancer appearance and motion reference.


Sources
arXiv: ACE-Step 1.5: Pushing the Boundaries of Open-Source Music Generation
arXiv: ACE-Step: A Step Towards Music Generation Foundation Model
GitHub: ace-step/ACE-Step-1.5
HuggingFace: ACE-Step/Ace-Step1.5
HuggingFace Space: ACE-Step/Ace-Step-v1.5
Project page: ace-step.github.io
AMD Developer Blog | Medium (@acemusic)
Continue Reading



Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Gemini Omni
- Google Veo 3.1
- Kling 3.0 Pro
- Luma Ray 3.2
- LTX 2.3
- Happy Horse 1.1
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace