Bernini: ByteDance Open Source Video Generation and Editing (Apache 2.0)

Share this post:
Bernini: ByteDance Open Source Video Generation and Editing (Apache 2.0)
ByteDance Research released Bernini on June 1, 2026, publishing the full model weights and inference code under the Apache 2.0 license, confirming commercial use. The model is built on top of the Wan 2.2 T2V-A14B base (14 billion parameters) and handles video generation and video editing in a single framework. Unlike Lance, ByteDance's earlier unified model, Bernini separates the work of understanding an edit from the work of rendering it.
Four Tasks, One Model
Bernini supports four core editing and generation tasks. The first is V2V, which edits an existing video using a text prompt. The second is RV2V, reference guided video editing, which takes a reference image alongside the source video and applies the reference image's content or visual style to the footage. The third is content insertion, which places a separate image or video clip directly into an existing video. The fourth is R2V, which generates a video from up to five reference images rather than from text alone.
In addition to these four editing tasks, Bernini also handles text-to-image, image editing, and text-to-video generation. The result is a model that covers both the creation side and the post production side of an AI video workflow under one Apache 2.0 license.
How It Works
Most open source video generation models condition image generation on text prompts alone. Bernini adds an upstream reasoning step. A multimodal language model acts as a semantic planner, reading the full set of inputs (text instruction, reference images, source video) and predicting a target semantic embedding before any pixel generation begins.
A DiT based renderer then runs flow matching denoising conditioned on that semantic embedding plus the original text and visual features. The model introduces Segment-Aware 3D Rotary Positional Embedding (SA-3D RoPE) to distinguish tokens from different visual segments during this process. SA-3D RoPE gives the model a way to track which tokens belong to the source video, which belong to a reference image, and which belong to an inserted clip, enabling chain of thought reasoning over the full multimodal input.
Reference Guided Video Editing in Practice

RV2V is the task that most directly addresses a recurring problem in AI video production: getting a model to apply a specific visual target to existing footage without describing that target in text. With RV2V, the reference image is a direct input alongside the source video. Bernini applies the content or appearance of the reference to the footage without requiring a text description of what the reference shows.

The R2V task extends this further. Rather than editing existing footage, R2V generates a new video from a set of up to five reference images. Filmmakers can supply reference photos of a character, a location, and a costume separately, and Bernini generates video that incorporates all of them. This is a meaningful extension beyond what text-to-video models allow, since the visual details in reference photos do not need to be translated into words at all. Explore these capabilities through the AI FILMS Studio video workspace.
Content Insertion
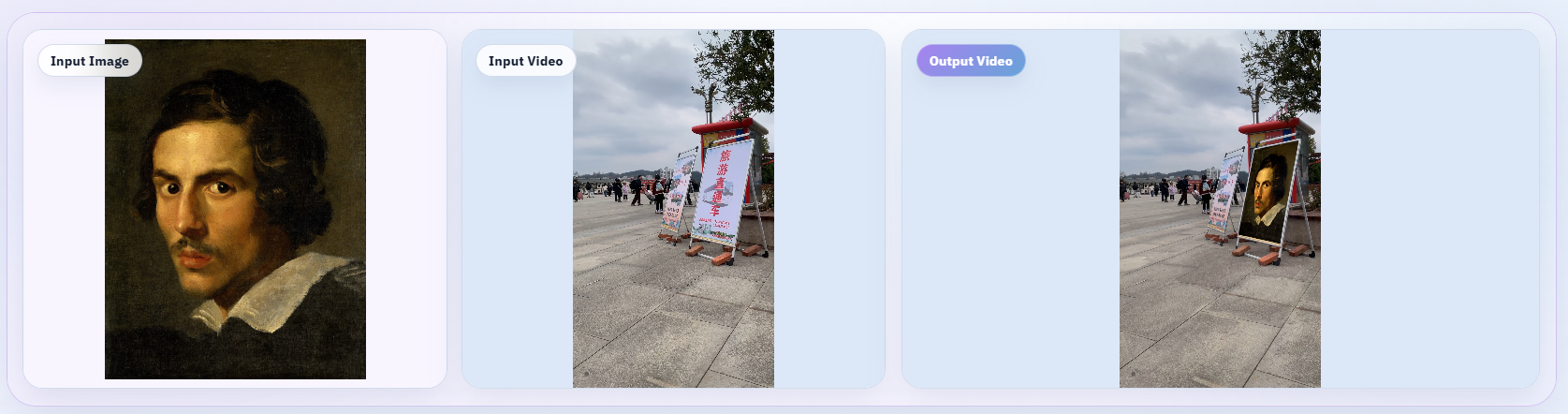
Content insertion is the task of embedding a specific image or video clip into an existing video in a way that respects the lighting, motion, and perspective of the scene. Bernini handles this as a native editing mode rather than as a compositing operation performed after generation. The SA-3D RoPE mechanism allows the model to track the spatial relationship between the inserted content and the existing footage during the denoising process.
Benchmark and Access
On a self-built human-annotated video editing arena using Bradley-Terry scoring and pairwise win-rate analysis, Bernini ranks in the first tier alongside leading commercial models for video editing tasks. The paper reports this result for the Bernini-R variant, which corresponds to the HuggingFace release at ByteDance/Bernini.
The model requires a Hopper GPU (H100, H800, or H200) for optimal performance with FlashAttention-3, CUDA 12.4 or higher, and Python 3.11.2. The recommended inference entry point is the official GitHub repository. A Gradio demo script (gradio_demo.py) is included in the repository for interactive testing. This follows in the line of ByteDance's recent open source research releases, which include Wan 2.2 Animate and the Lance unified generation model.


Sources
Project page: bernini-ai.github.io
GitHub: bytedance/Bernini
HuggingFace: ByteDance/Bernini
HuggingFace (Diffusers): ByteDance/Bernini-R-Diffusers
arXiv: Bernini: Latent Semantic Planning for Video Diffusion
License: Apache 2.0
Continue Reading



Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Gemini Omni
- Google Veo 3.1
- Kling 3.0 Pro
- Luma Ray 3.2
- LTX 2.3
- Happy Horse 1.1
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace