Causal rCM: NVIDIA Open-Sources Real Time Video Diffusion Distillation

Share this post:
Causal rCM: NVIDIA Open-Sources Real Time Video Diffusion Distillation
Causal rCM is a video diffusion distillation method from NVIDIA's Cosmos Lab, released June 25, 2026, that compresses the standard 50 to 100 step inference process down to 1 to 2 steps without a proportional quality drop. The paper extends the team's rCM (score regularized continuous time consistency model) technique with a streaming, frame by frame generation mode that enables real time interactive video output.
The full codebase is available on GitHub under the Apache 2.0 license, confirmed in the repository's LICENSE.txt file. The release includes not just pretrained distilled weights, but the complete training recipe, including a custom FlashAttention-2 JVP (Jacobian vector product) kernel for distributed training at 10 billion plus parameter scale.
Causal rCM teaser: real time video generation at 1 to 2 inference steps, from NVIDIA's Cosmos Lab
From 100 Steps to 2: What Distillation Achieves
Standard video diffusion models require 50 to 100 forward passes through the neural network per generated clip. Each pass refines the output progressively, starting from random noise and converging toward a coherent video. That iterative process is why generation time on current hardware is measured in seconds to minutes, not frames per second.
Consistency models learn to map directly from a noisy input to the clean output in a single step, bypassing the iterative refinement chain. Distillation trains a compressed student model to approximate the outputs of a larger teacher, transferring quality without duplicating the computational cost. Causal rCM combines both techniques, training a student model under the score regularized consistency model framework and achieving 1 to 2 step sampling using a 1.3 billion parameter student built on Wan2.1.
The VBench-T2V benchmark score for the distilled model at 1 to 2 steps is 84.63, published in the paper. VBench-T2V evaluates text-to-video generation quality across 16 dimensions, covering subject consistency, background stability, motion smoothness, and prompt alignment.
| Model | Inference Steps | VBench-T2V | License |
|---|---|---|---|
| Causal rCM (Wan2.1 1.3B student) | 1 to 2 | 84.63 | Apache 2.0 |
| Wan2.1 teacher | 50 to 100 | baseline | Apache 2.0 |
| StreamDiffusion (benchmark reference) | streaming | lower | varies |
| StreamV2V (benchmark reference) | streaming | lower | varies |
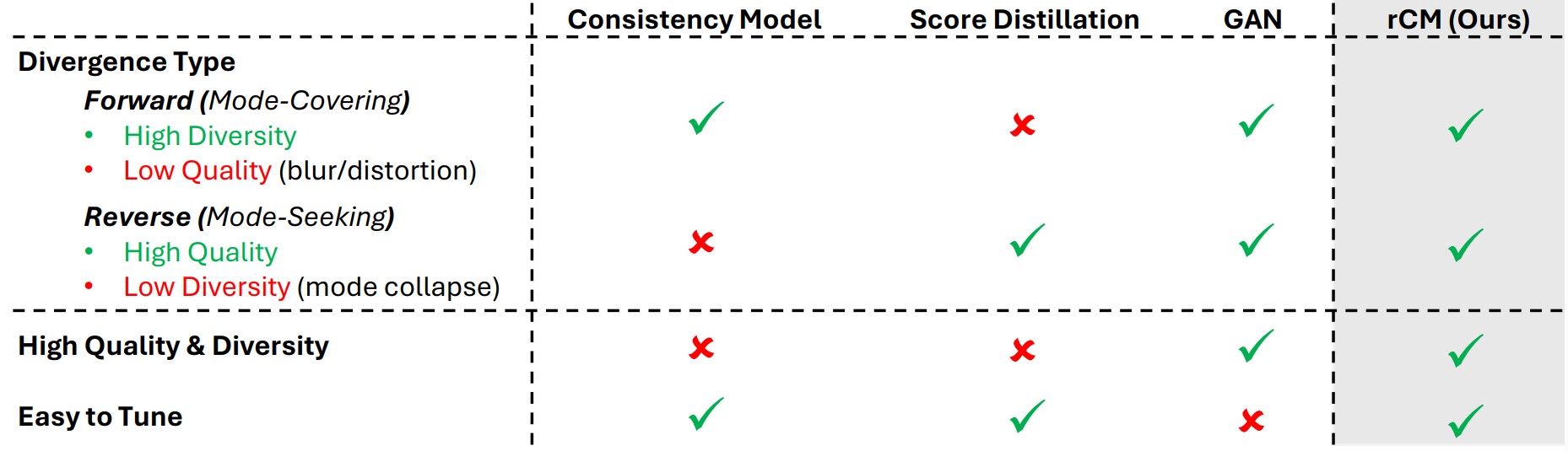
The rCM Architecture
Source: NVIDIA Research, Cosmos Lab
The rCM framework introduces score regularization into the consistency model training process. Standard consistency models can suffer from training instability at large parameter scales. Score regularization anchors the student model's outputs against the teacher diffusion model's score function during training, stabilizing the distillation at the scales needed for high quality video generation.
The framework operates in continuous time, meaning the model is not restricted to a fixed set of discretized diffusion timesteps. Continuous time training lets the student learn from the full distribution of noise levels rather than a sampled subset, which is one reason the distillation maintains quality under aggressive step reduction. The combination of score regularization and continuous time training is what distinguishes rCM from earlier consistency distillation methods.
How the Causal Extension Works
The "Causal" in Causal rCM names the autoregressive generation mode the extension paper adds. The base rCM model generates all video frames in a single batch. The causal variant generates frames sequentially, each conditioned on previously generated frames rather than on an ungenerated sequence. That change is what allows video output to begin streaming before the full clip is complete.
Temporal consistency across the streaming output is maintained through a cached key value mechanism that avoids recomputing past frame representations on every generation step. As new frames are generated, the cache carries forward the computed context from earlier frames, keeping motion and appearance coherent across the clip without requiring a second full pass over prior frames.
The practical result is that a production pipeline can receive and display the first frames of a generation while subsequent frames are still being computed. That streaming behavior is the foundation for the "real time" framing in the paper's title.
Source: NVIDIA Research, Cosmos Lab
Generation Quality at 1 to 2 Steps

Source: NVIDIA Research, Cosmos Lab
The 84.63 VBench-T2V score at 1 to 2 steps places Causal rCM at the high end of open source distillation releases. Achieving this at near single step sampling is the paper's core empirical contribution. Competing distillation methods typically require 4 to 8 steps to reach comparable quality scores on the same benchmark.
The student model's 1.3 billion parameters match the scale of other Wan2.1 based releases, enabling direct benchmark comparisons without a separate evaluation baseline. The choice of Wan2.1 as the student architecture also means the distilled model benefits from the same community infrastructure, including model conversion tools and inference libraries, that has built up around that base.
Specific per method benchmark comparisons beyond the 84.63 headline figure are available in the arXiv paper. The paper includes a comparison table covering the teacher model and other distillation baselines across multiple VBench dimensions.
Step Count and Quality Tradeoffs
A distillation release rated for 1 to 4 steps may perform well at 4 but degrade at 1. The paper addresses this directly, reporting quality measurements across the full supported step range. Practitioners can choose the step count that matches their latency and quality requirements rather than accepting a single fixed setting.
At 4 steps the model runs slower than at 1 to 2, but outputs move closer to the full teacher model's quality. The step count becomes a tunable parameter, useful for workflows where some prompts require more generation detail than others. A production pipeline can apply different step budgets per task category, for example using 1 step for rapid concept visualization and 4 steps for final output review.

Source: NVIDIA Research, Cosmos Lab
Open Sourcing the Training Recipe
Most distillation releases provide inference weights and a generation script. Running a predistilled model is straightforward, but replicating the distillation process on a different base model, or scaling the technique to a larger parameter count, requires the training code and the specialized kernels that make distributed training feasible at scale.
Causal rCM includes both. The repository ships the training codebase alongside a custom FlashAttention-2 JVP kernel written for the gradient computations that consistency model distillation training requires. Standard FlashAttention-2 is optimized for forward pass inference, not the Jacobian vector product calculations involved in distillation. NVIDIA wrote and open-sourced the specialized kernel to make their distillation training process reproducible on other hardware setups.
The kernel supports FSDP (Fully Sharded Data Parallel) and context parallel distributed training configurations, the two main strategies for scaling transformer training across multiple nodes. The released training code is usable at 10 billion plus parameter scales, not just at the 1.3 billion scale demonstrated in the paper. A team with sufficient hardware can distill their own large video model using the Causal rCM approach rather than depending on NVIDIA's released checkpoints.
Apache 2.0 License and Access
Causal rCM is released under the Apache 2.0 license, confirmed by reading the LICENSE.txt file in the NVlabs/rcm GitHub repository. Apache 2.0 permits commercial use, modification, and redistribution without royalty obligations. Both the inference code and the training code fall under the same license.
The pretrained weights for the Wan2.1 based student model are available on HuggingFace at worstcoder/rcm-Wan. Installation and inference instructions are in the GitHub repository. A community demo Space exists on HuggingFace (linoyts/wan2-2-i2v-rCM), but it is a third-party contribution and was in a paused state at time of writing. The project page and GitHub repository are the stable access points for the model.
The training code, including the FlashAttention-2 JVP kernel, ships in the same repository as the inference code. No separate license or access request is required for the training components.
Where Causal rCM Fits
NVIDIA's Cosmos Lab has published open source video generation work across different technical problems. LongLiVe targets long form video coherence, extending generation to minutes-length clips through context compression and frame selection. Causal rCM addresses a different constraint: reducing inference cost per clip regardless of clip length, so that generation speed itself becomes a workable tool in production.
The most direct comparison for Causal rCM is the quantization aware distillation approach in FastWan, which achieves fast inference through weight quantization and structural pruning rather than consistency model training. Both target the same speed problem using architecturally distinct strategies. Quantization aware distillation preserves the original model structure while reducing numerical precision. Causal rCM changes the generation process itself, collapsing multi-step diffusion into a learned direct mapping. The additional training recipe transparency sets Causal rCM apart from most speed-focused releases: FastWan ships inference optimizations, while Causal rCM ships the complete distillation training pipeline for teams that want to apply the technique to their own models.
Filmmakers and editors generating video for production use can work with text-to-video and image-to-video tools at AI FILMS Studio.


Sources
arXiv: Causal rCM: Large Scale Diffusion Distillation (2606.25473) GitHub: NVlabs/rcm Project Page: NVIDIA Research, rCM HuggingFace: worstcoder/rcm-Wan
Continue Reading



Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Google Veo 3.1
- Kling 3.0 Pro
- LTX 2.3
- Happy Horse 1.0
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace