FastWan-QAD: Ultrafast Open Source Video Generation by Hao AI Lab

Share this post:
FastWan-QAD: Ultrafast Open Source Video Generation by Hao AI Lab
FastWan-QAD generates a 5 second 480p video in approximately 3.4 seconds on a single RTX 4090, released under Apache 2.0 by Hao AI Lab at UC San Diego. The model distills Wan 2.1 down to 1.3 billion parameters at FP8 precision using quantization aware distillation (QAD), a training method that preserves generation quality while cutting inference time to near real time on consumer hardware.

What Quantization Aware Distillation Changes
Standard post training quantization compresses a model after training finishes, which degrades output quality because the model was never trained to compensate for the information lost during compression. FastWan-QAD builds that compensation into the distillation objective itself.
During training, the model learns not just to generate video but to generate video at 1.3 billion parameters and FP8 precision without visible degradation. By inference time, the artifacts that typically appear in compressed video models have already been absorbed into the learned weights. The result is output competitive with the full size base model at 480p resolution, without the quality collapse that characterizes systems compressed aggressively with PTQ.
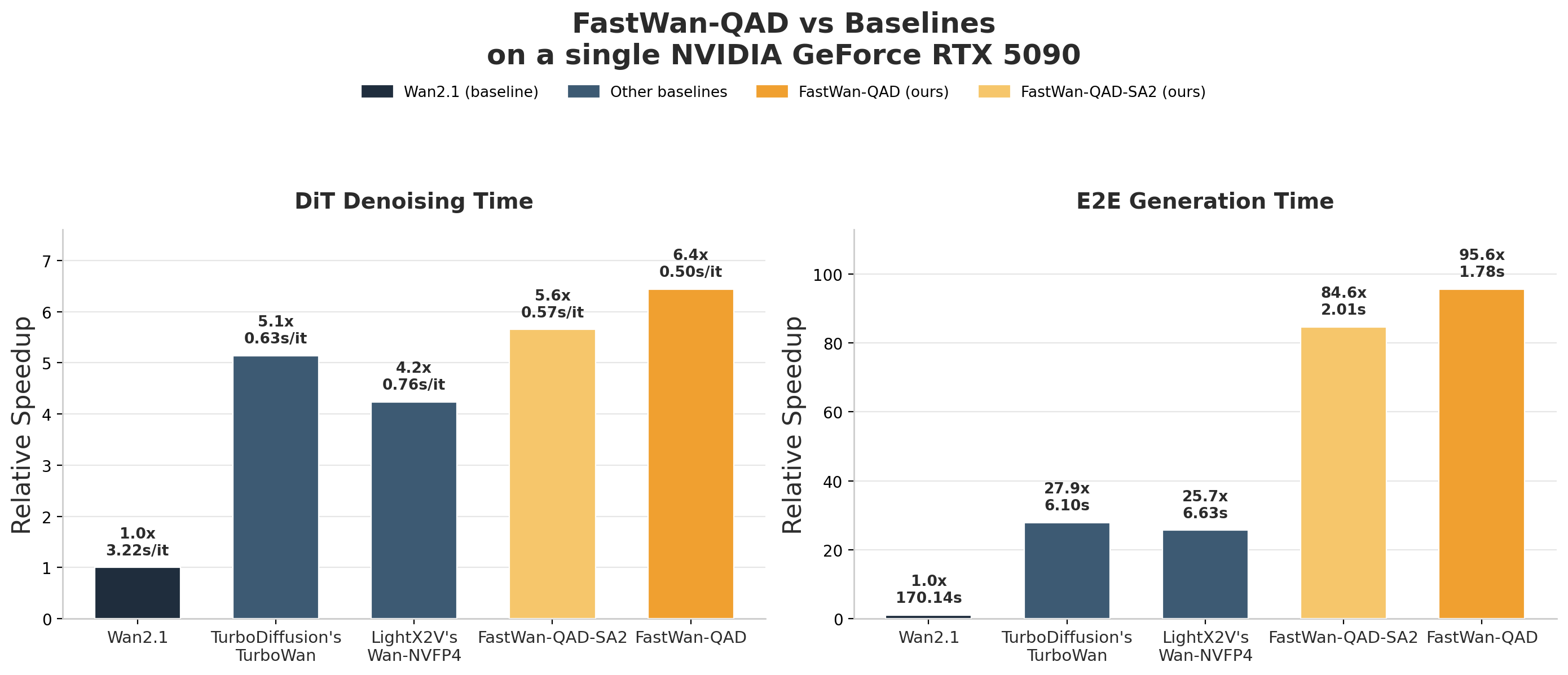
The Benchmark
FastWan-QAD runs 3 denoising steps using SageAttention2++ as the attention backend. The official benchmark from the Hao AI Lab model card:
| Metric | Value |
|---|---|
| Resolution | 832×480 pixels |
| Duration | 5 seconds (81 frames at 16 fps) |
| Inference time | ~3.4 seconds |
| Test hardware | Single RTX 4090 |
| Parameters | 1.3 billion |
| Precision | FP8 |
| Denoising steps | 3 |
Compatible GPU architectures are Ampere and Ada. The 3.4 second figure is the official 480p benchmark; no higher resolution benchmarks have been published.
Example Outputs
The following outputs are generated with the FastWan-QAD FP8 model:



Architecture and Setup
The model is built on Wan 2.1, distilled and quantized at 1.3 billion parameters using FP8 linear layers throughout. SageAttention2++ handles the attention computation, contributing to inference speed alongside the parameter reduction. The 3 step distillation pipeline lets the model skip the majority of denoising iterations required by the full size base.
Hao AI Lab has published the full codebase and inference instructions on GitHub under the FastVideo project. Weights are on HuggingFace. The Apache 2.0 license covers research and commercial use with no royalty requirements, and the model runs on any Ampere or Ada GPU without additional licensing steps.
For broader context on the open source video generation landscape, MoVA and Lumos-Nexus take different architectural approaches to the quality and speed tradeoff in open source video generation.
Filmmakers who want to generate AI video without a local GPU setup can use AI FILMS Studio to access text-to-video and image-to-video tools directly in the browser.


Sources
Hao AI Lab Blog: FastWan-QAD GitHub: hao-ai-lab/FastVideo HuggingFace: FastVideo/FastWan-QAD-FP8-1.3B arXiv: 2603.00040
Continue Reading
.jpg?w=3840)


Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Google Veo 3.1
- Kling 3.0 Pro
- LTX 2.3
- Happy Horse 1.0
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace