MultiShotMaster: Multi Shot Narrative Video Generation From Kling

Share this post:
MultiShotMaster: Multi Shot Narrative Video Generation From Kling
Generating a single video clip with AI is no longer the hard part. The real challenge is stringing multiple shots together into a coherent narrative where characters look the same, scenes stay consistent, and the story actually flows. MultiShotMaster, a new open source framework from the Kling team at Kuaishou Technology, tackles this problem directly. Accepted at CVPR 2026 and winner of first place at the AAAI CVM 2026 Main Track, the project extends pretrained video generation models to produce multi shot videos with flexible shot counts, consistent subjects, and controllable scenes.
What MultiShotMaster Actually Does
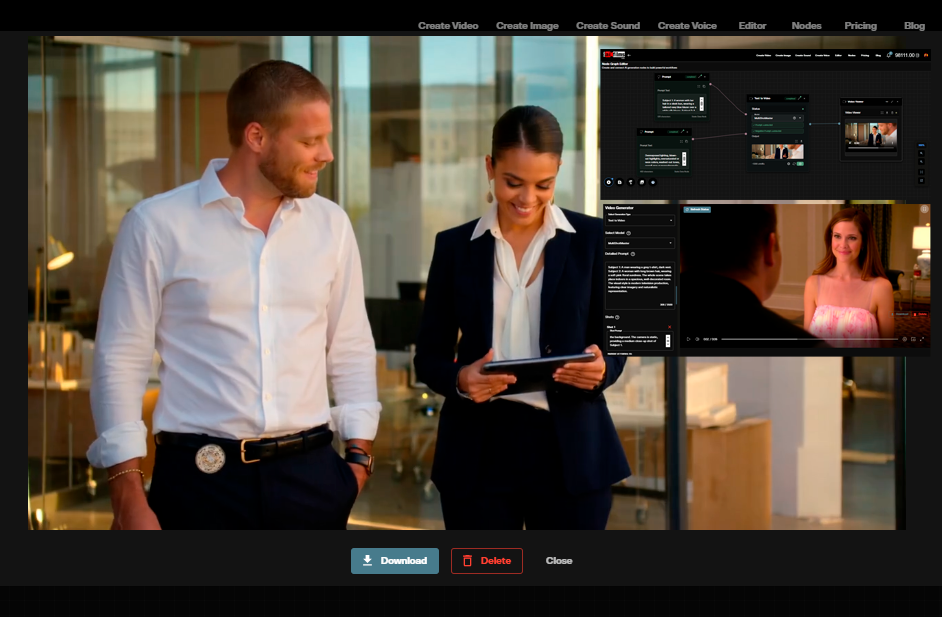
Most text-to-video models generate isolated clips. Each prompt produces a standalone shot with no memory of what came before. MultiShotMaster changes this by taking a set of instructions, including a global description and per shot captions, along with reference images for characters and backgrounds, and producing a sequence of video shots that maintain visual consistency across the entire narrative.
The framework supports between one and five shots in a single generation pass, with up to 308 frames total. You can control who appears in each shot, what background is used, and how shots transition from one to the next. This is not simple video concatenation. The model generates all shots in a unified process that preserves identity and scene coherence.
The Architecture Behind It
MultiShotMaster introduces two key technical innovations built on top of existing video diffusion models.
Multi Shot Narrative RoPE
Standard Rotary Position Embeddings (RoPE) treat video frames as a single continuous sequence. This works for one shot but breaks down when you need distinct shots with their own temporal structure. Multi Shot Narrative RoPE applies explicit phase shifts at shot boundaries, so each shot gets its own temporal context while the overall narrative flow is preserved. This allows the model to handle variable shot durations and flexible arrangements without losing coherence.
Spatiotemporal Position Aware RoPE
The second innovation handles reference injection. When you provide a character photo or background image, the model needs to know where and when that reference should appear. Spatiotemporal Position Aware RoPE embeds reference tokens with grounding signals, essentially telling the model "this character appears at this location in this shot." This enables precise spatial control through bounding boxes, so you can place subjects exactly where you want them across different shots.
The framework also uses a Multi Shot and Multi Reference Attention Mask that controls information flow between shots and reference materials, preventing visual leakage while maintaining consistency where needed.
Key Capabilities
MultiShotMaster offers four main control mechanisms for filmmakers and creators.
Text driven inter shot consistency. A global caption defines the overall scene, characters, and environment. Per shot captions specify the action, background, and camera movement for each individual shot. The model maintains character identity across all shots using only these text descriptions.
Customized subjects with motion control. Supply reference images of specific characters, and the model preserves their appearance across every shot. Combined with per shot text descriptions, you can direct character movement and action while maintaining visual identity. For precise motion transfer within individual shots, Kling 3.0 Motion Control provides native support for driving character body movement and facial expressions from reference video.
Background driven scene customization. Provide background reference images to control the setting of each shot. The model separates subject and background, allowing you to change environments between shots while keeping the same characters.
Flexible shot count and duration. Configure anywhere from one to five shots with variable frame counts per shot, all generated in a single pass. Total capacity reaches 308 frames across all shots.
Model Variants and Specs
The team released two model sizes, each targeting different hardware and quality tiers.
| Model | Resolution | Parameters | Use Case |
|---|---|---|---|
| 1.3B | 480p (832x480) | 1.3 billion | Faster inference, lower VRAM |
| 14B | 480p and 720p | 14 billion | Higher quality, more detail |
The 14B model generates at both 480p (832x480) and 720p (1280x720) resolutions, making it suitable for higher quality productions. The 1.3B model is limited to 480p but requires significantly less compute.
Data Pipeline
Training data for multi shot videos is scarce. To solve this, the team built an automated annotation pipeline that processes existing video content into training pairs. The pipeline uses shot transition detection models to segment videos into individual shots, then clusters clips by scene using segmentation. Hierarchical captions (global plus per shot) are generated via Gemini 2.5. Subject images are extracted through YOLOv11, ByteTrack, and SAM integration, and clean backgrounds are produced using OmniEraser.
This pipeline is significant because it means the approach is not bottlenecked by manually annotated training data. Any large video corpus can be automatically processed into usable training material.
Installation and Local Setup
MultiShotMaster is fully open source under the Apache 2.0 license. Here is what you need to run it locally.
Requirements
- Python 3.12
- CUDA compatible GPU (the 14B model needs substantial VRAM)
- conda for environment management
- Key dependencies: flash-attn, huggingface-hub
Setup Steps
Clone the repository from GitHub:
git clone https://github.com/KlingAIResearch/MultiShotMaster.git
cd MultiShotMaster
Create and activate the conda environment, then install dependencies including flash-attn and huggingface-hub as specified in the repository.
Download model weights via huggingface-cli or git-lfs from the Hugging Face repository. Both the 1.3B and 14B checkpoints are available. Model paths are configured through JSON files in the checkpoints/model_configs/ directory.
Running Inference
For single GPU inference with the 1.3B model:
python infer_multishot.py --test_csv_path "toy_cases/test_multishot.csv" \
--output_name "1.3B" \
--model_path_json "checkpoints/model_configs/model_path_1.3B.json" \
--target_width 832 --target_height 480
Multi GPU inference is supported through torchrun with distributed processing. Training scripts for both single node and multi node setups are also included if you want to fine tune the model on your own data.
Input configuration uses CSV files that specify shot groups and frame counts, with shot captions defined in JSON format combining global context with per shot descriptions.
License and Commercial Use
MultiShotMaster is released under the Apache 2.0 license, which permits both personal and commercial use. You can modify, distribute, and use the code and models in commercial products without restrictions beyond standard Apache 2.0 terms (attribution and license notice). This makes it one of the more permissive multi shot video generation tools available for production use.
Limitations
Despite its strengths, MultiShotMaster has clear boundaries.
- Maximum five shots per generation. Longer narratives require chaining multiple generation passes, which may introduce inconsistencies at the boundaries.
- Resolution ceiling. The 14B model caps at 720p, and the 1.3B model at 480p. Neither reaches the 1080p or 4K resolutions that professional production typically demands.
- Hardware requirements. The 14B model requires significant GPU memory. Running it locally means investing in high end hardware.
- Frame limit. With a maximum of 308 frames across all shots, total video duration is limited to roughly 10 to 12 seconds depending on framerate.
- No audio generation. The framework produces video only. Sound design, dialogue, and music must be handled separately.
Why This Matters for AI Filmmaking
Multi shot consistency has been one of the biggest obstacles in AI filmmaking. Generating a single beautiful shot is routine now. Making three shots that look like they belong in the same scene, with the same characters, wearing the same clothes, in the same location, has been where AI video breaks down. MultiShotMaster is a meaningful step toward solving that problem at the architectural level rather than through post production workarounds.
For filmmakers experimenting with AI tools on AI FILMS Studio, understanding these developments helps contextualize what is becoming possible. The shift from isolated clip generation to structured multi shot narratives represents a fundamental evolution in how AI video tools will work. Combined with tools for AI generated images, these multi shot capabilities point toward a future where AI can handle entire sequences rather than just individual moments.
Projects like StoryMem and HoloCine have explored similar territory, but MultiShotMaster's open source release with Apache 2.0 licensing and its CVPR 2026 acceptance mark it as a particularly significant contribution to the field.


Sources
Qinghe Wang et al.: "MultiShotMaster: A Controllable Multi-Shot Video Generation Framework" arXiv:2512.03041, December 2025 https://arxiv.org/abs/2512.03041
Project Page: MultiShotMaster https://qinghew.github.io/MultiShotMaster/
GitHub Repository: KlingAIResearch/MultiShotMaster https://github.com/KlingAIResearch/MultiShotMaster
Hugging Face: KlingTeam/MultiShotMaster https://huggingface.co/KlingTeam/MultiShotMaster
Continue Reading



Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Gemini Omni
- Google Veo 3.1
- Kling 3.0 Pro
- Luma Ray 3.2
- LTX 2.3
- Happy Horse 1.1
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace