MOSS-TTS Local Transformer v1.5: 48 kHz Voice Cloning with Dialogue Timing Control

Share this post:
MOSS-TTS Local Transformer v1.5: 48 kHz Voice Cloning with Dialogue Timing Control
OpenMOSS Team and MOSI.AI have released MOSS-TTS Local Transformer v1.5, a 5 billion parameter text to speech model that generates native 48 kHz stereo audio from a single reference clip across 31 languages. The model is released under Apache 2.0, permitting commercial use without restrictions beyond license inclusion. It accumulated 697,870 downloads in one month on HuggingFace, the highest figure across the MOSS audio model family.
MOSS-TTS Local Transformer v1.5: voice cloning and dialogue synthesis overview
What Changed in v1.5
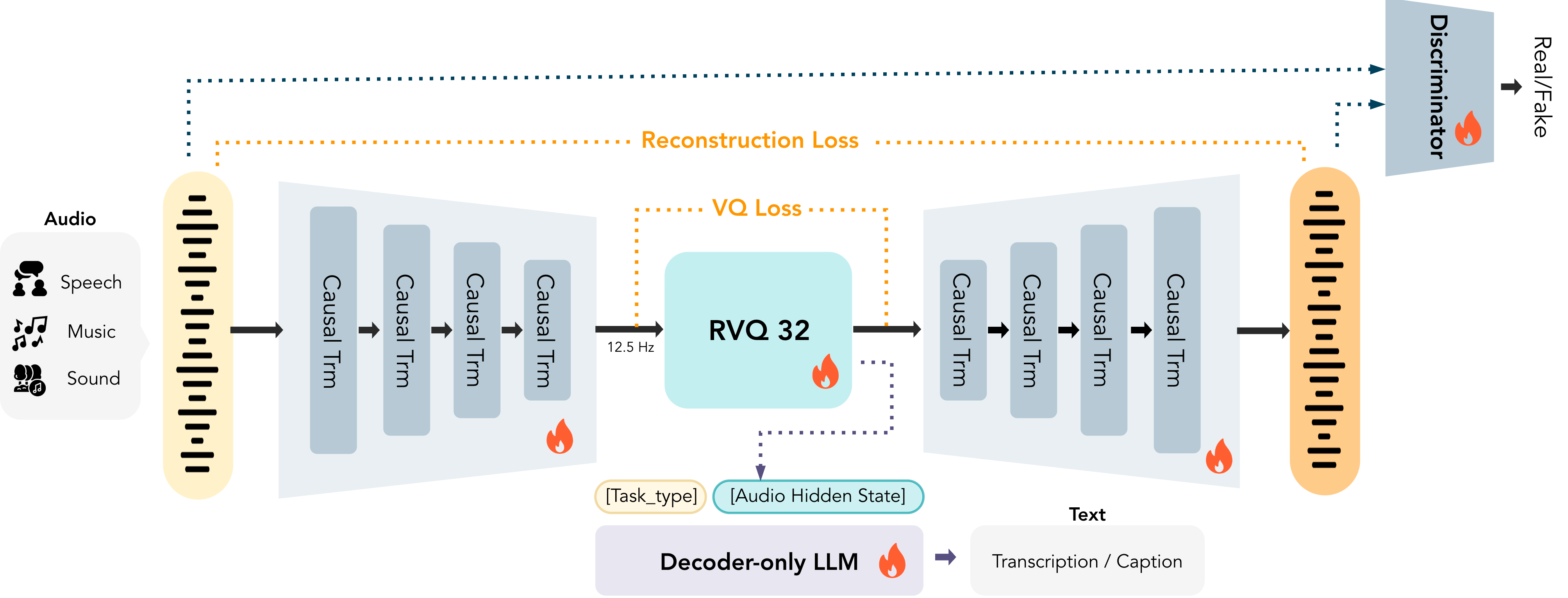
The primary upgrade in v1.5 is the audio tokenizer. The original MOSS-TTS used a 24 kHz mono encoder. Local Transformer v1.5 integrates MOSS-Audio-Tokenizer-v2, a 1.6 billion parameter encoder running at 48 kHz stereo with a 32-layer residual vector quantization scheme at 12.5 Hz frame rate. Stereo output at 48 kHz matches the sampling rate of professional studio recordings and can be placed directly into post production timelines without upsampling.
Three additional changes ship with v1.5. Speaker similarity is more stable across repeated generations, reducing variance when cloning a voice across multiple takes of the same script. Prosody follows punctuation more consistently, meaning commas and full stops produce reliable pauses rather than flat delivery. The model also handles reference audio that significantly exceeds the length of the target text more reliably than v1.0.
Zero Shot Voice Cloning
MOSS-TTS-Local-Transformer-v1.5 clones any voice from a single reference audio clip with no fine tuning required.
The tokenizer separates speaker identity from acoustic content during encoding. This separation allows the model to generate speech in languages the reference speaker never recorded. A voice profile derived from English reference audio can produce fluent Japanese, Arabic, or Spanish with consistent speaker characteristics across all 31 supported languages.
Code switching is also supported: a single output clip can alternate between two languages within the same utterance. This is useful for bilingual content without reprocessing audio from separate generation passes.
The MOSS-SoundEffect v2.0 model from the same team generates environmental audio and Foley at the same 48 kHz standard, enabling a production pipeline where dialogue and sound effects share the same sampling specification without format conversion.
Dialogue Timing Control
MOSS-TTS introduces explicit pause syntax: [pause X.Ys] inserted directly into text input specifies pause duration in seconds at that position. A script segment reading "She considered it. [pause 1.8s] Then she agreed." produces exactly 1.8 seconds of silence at the marked point, rather than an inferred pause from punctuation alone.
This matters in voice production because it removes manual gap insertion from audio editing. Writers who set pause timing at the text level do not need to open an audio editor to adjust rhythm between lines.
Multi-speaker dialogue extends this control through MOSS-TTSD, a companion system in the same repository. MOSS-TTSD generates conversations between multiple speakers with coordinated turn taking timing. On objective evaluation it achieved speaker similarity scores of 0.7949 in Chinese and 0.7326 in English, with word accuracy rates of 95.87% and 96.26% respectively, according to the MOSS-TTS technical report.
Compared to approaches like dots.tts, which prioritizes low-latency streaming at 54ms time to first byte, MOSS-TTS Local Transformer v1.5 optimizes for production audio quality and explicit timing control over real time inference.
Architecture: MossTTSLocal and Audio Tokenizer v2
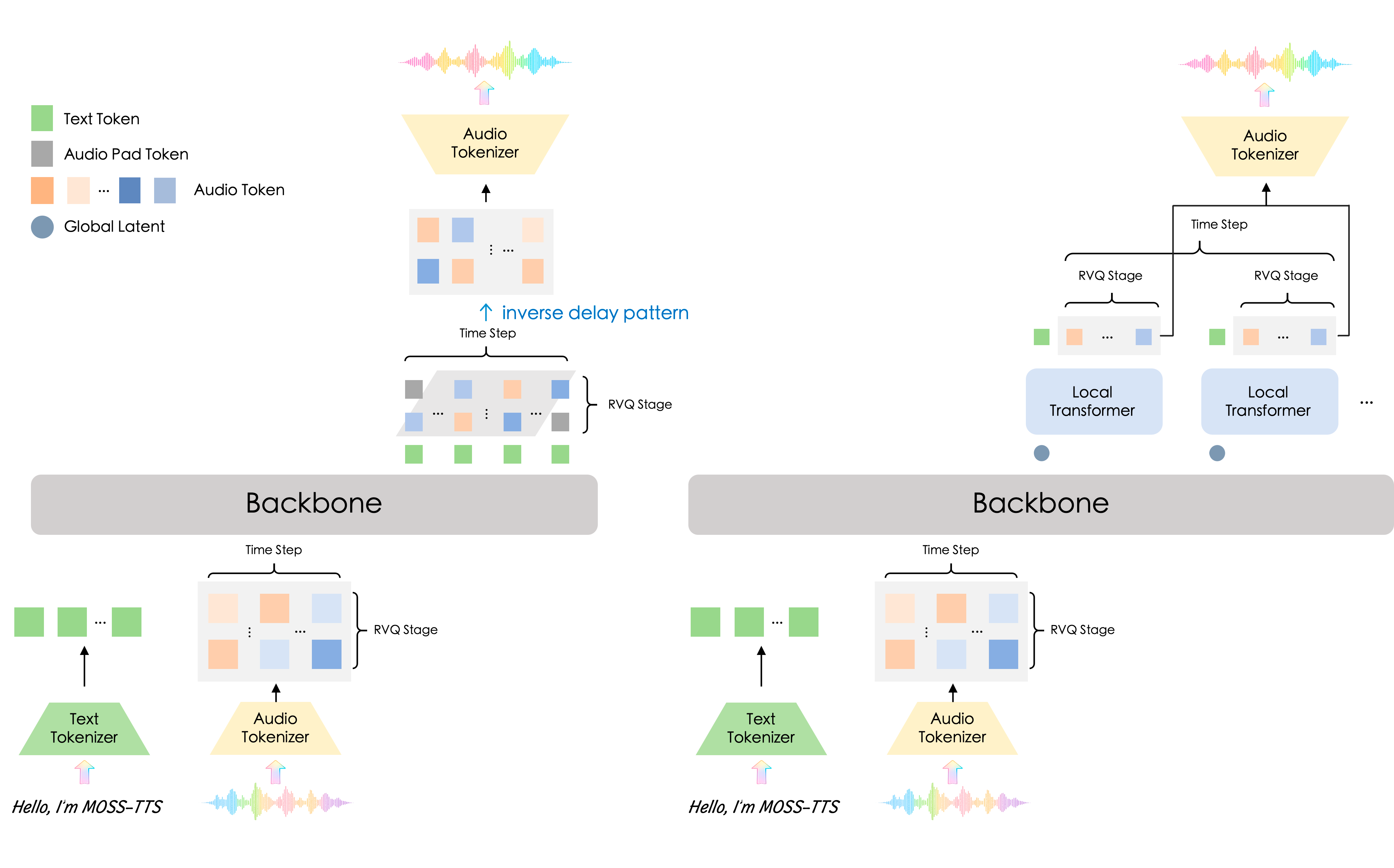
MOSS-TTS-Local-Transformer-v1.5 runs the MossTTSLocal architecture, which pairs time synchronous residual vector quantization blocks with a depth transformer. Time synchronous processing means the model generates audio tokens in step with input text tokens rather than completing all tokens in parallel then reordering. This design makes the model streaming compatible. Output begins before the full input has been processed.
MOSS-Audio-Tokenizer-v2 operates at a 12.5 Hz frame rate with 32 RVQ layers and a variable bitrate range of 0.125 to 4 kbps. The variable rate allocates more bits to acoustically complex passages such as fricatives and consonant clusters, rather than applying uniform compression across the utterance.
The companion model MOSS-TTS-v1.5 uses the MossTTSDelay architecture at 8 billion parameters. MossTTSDelay uses parallel RVQ prediction with delay pattern scheduling optimized for production use where streaming latency is not a constraint. Both models share MOSS-Audio-Tokenizer-v2 and output at identical audio specifications. The Local Transformer at 5B parameters is the more accessible entry point; MossTTSDelay adds generation quality at higher memory cost.
Additional input controls available in both architectures include Pinyin and IPA phoneme specification for pronunciation accuracy, and token level duration adjustment for more precise pacing beyond the pause marker syntax.
Benchmark Performance
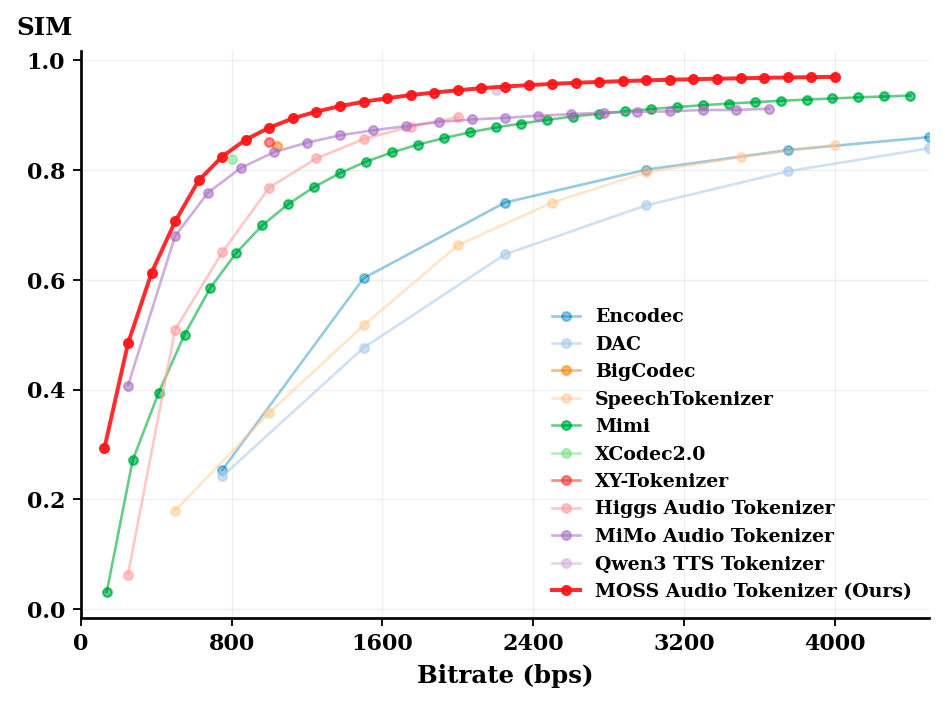
On the Seed-TTS-eval benchmark, MOSS-TTS achieves 1.84% word error rate in English and 1.37% character error rate in Chinese. Speaker similarity scores are 70.86% for English and 76.98% for Chinese, placing it alongside leading closed source models on the same evaluation.
The audio understanding counterpart MOSS-Audio covers speech recognition and music analysis across model variants from 4.6B to 8.6B parameters under the same Apache 2.0 license. Together, the two models cover generation and comprehension within a single open source audio pipeline from the same team.
Live Demo
The MOSS-TTS Local Transformer v1.5 interface is publicly available on HuggingFace. The demo accepts text input, an optional reference audio clip for voice cloning, and a language selector across all 31 supported languages.
Voice generation and voice cloning tools are also available directly in the AI FILMS Studio voice workspace.


Sources
arXiv: MOSS-TTS: A Production-Grade Open-Source TTS System arXiv: MOSS-TTSD: Multi-Speaker Dialogue Speech Synthesis GitHub: OpenMOSS/MOSS-TTS HuggingFace: OpenMOSS-Team/MOSS-TTS-Local-Transformer-v1.5 HuggingFace: OpenMOSS-Team/MOSS-Audio-Tokenizer-v2
Continue Reading
.jpg?w=3840)


Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Google Veo 3.1
- Kling 3.0 Pro
- LTX 2.3
- Happy Horse 1.0
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace