FreeStyle: Style and Content Dual Reference Image Generation via Community LoRA Mining

Share this post:
FreeStyle: Style and Content Dual Reference Image Generation via Community LoRA Mining
FreeStyle is an open source image generation system published in June 2026 by researchers at Fudan University, StepFun, Westlake University, and the University of Hong Kong. It takes two reference images alongside a text prompt: one image supplies the visual style, and a second supplies the content subject. The model generates a new image that adopts the style of the first reference while depicting the subject of the second.
The system is released under the Apache 2.0 license, permitting commercial use. Model weights and code are publicly available.
Dual Reference Generation
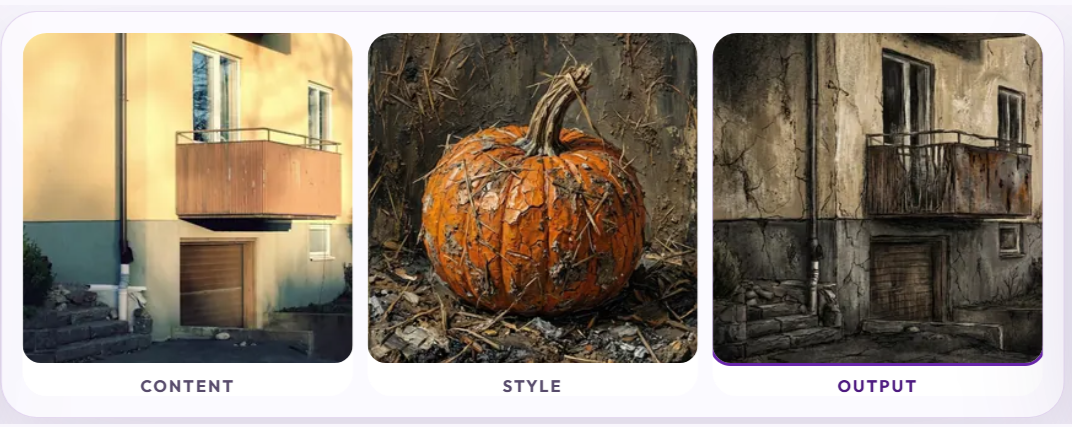
Standard image generation models accept a text prompt. Style transfer models typically accept one reference image. FreeStyle accepts two. A style reference defines the visual language: the color palette, brushwork, rendering quality, or photographic treatment the output should match. A content reference defines what the image should depict: a character, an object, a scene composition.

Example output from the FreeStyle project page, demonstrating style preservation with a separate content reference.
The key technical challenge in this kind of generation is content leakage, where the model blends elements of both references in ways the user did not intend. FreeStyle addresses this by treating style and content as separate conditioning signals with distinct pathways through the generation process. The paper reports that the system achieves strong style preservation while keeping content references clean and distinct.
Mining the Community's LoRA Library
The distinguishing technical choice in FreeStyle is how it represents styles and content categories. Instead of training on a fixed proprietary dataset, the system mines the open source community's existing LoRA weight collections. Each LoRA functions as a clustering center for a style or a content concept. The model learns to use these weights as anchors, allowing it to compose style and content conditioning from the vocabulary the community has already built and published.
This approach has a direct practical consequence. FreeStyle's stylistic range grows as the LoRA community publishes new weights, without any retraining of the FreeStyle model itself. A LoRA published for a specific film grain treatment or a particular illustration style can be referenced in FreeStyle generation immediately. No proprietary style catalog is required, and no API call is gated behind a subscription.
A second FreeStyle output showing how content and style references combine without leaking across conditioning signals.
Performance and How to Access It
The paper, published as arXiv preprint 2606.20506, reports that FreeStyle outperforms baseline methods on style preservation metrics in ablation studies across both the style-only (SRef) and dual reference (SRef + CRef) task settings. The FreeStyle_Bench dataset, also publicly released, provides a structured evaluation set for comparing future methods against the same conditions.
The system supports two operational modes. Style reference only (SRef) applies a source style to a text prompted generation. Combined style and content reference (CRef + SRef) adds the second conditioning signal for subject control. Weights are available through HuggingFace under the Blue2Giant organization, with separate checkpoints for each mode. The corresponding authors are Gang Yu (Westlake University) and Chi Zhang (University of Hong Kong).
Production Applications
For filmmakers, FreeStyle addresses a specific problem in the visual development phase, specifically generating reference images that faithfully match an established visual style while depicting new subjects. A cinematographer can supply a frame from an established visual grammar as the style reference and a character concept as the content reference, generating consistent production imagery without manual compositing.
The same workflow applies to concept art and production design. An art director can iterate rapidly across a scene's visual treatment while holding the character reference constant, or hold the visual treatment constant while testing new subjects. For mood board work, the model can generate multiple framings in a consistent style from a single style reference image. Filmmakers working with AI FILMS Studio's image workspace and building on open source image generation models like HiDream O1 can add FreeStyle's style and content conditioning as a complementary local tool in their pipeline.
The LoRA mining approach also connects to FLUX.2 and the broader ecosystem of open image generation models. As the community produces new LoRAs trained on specific visual treatments and director styles, those LoRAs become usable as FreeStyle style references immediately.


Sources
arXiv: FreeStyle: Free Control of Style Content Generation from Community LoRA Mining GitHub: Blue2Giant/FreeStyle HuggingFace: Blue2Giant/FreeStyle_Checkpoint Project Page: blue2giant.github.io/FreeStyle
Continue Reading



Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Google Veo 3.1
- Kling 3.0 Pro
- LTX 2.3
- Happy Horse 1.1
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace