Moebius: 0.22B Open Source Inpainting Model That Matches 11.9B Quality

Share this post:
Moebius: 0.22B Open Source Inpainting Model That Matches 11.9B Quality
Researchers at Huazhong University of Science and Technology (HUST) and VIVO AI Lab released Moebius on June 18, 2026. The model is accepted at ECCV 2026, the European Conference on Computer Vision, and both code and weights are available under open source commercial licenses.
The headline claim is specific: Moebius has 0.22 billion parameters and matches or exceeds the output quality of FLUX.1-Fill-Dev, Black Forest Labs' inpainting model at 11.9 billion parameters, while running more than 15 times faster. That is a 54x parameter reduction at comparable benchmark performance.

What Image Inpainting Does for Production
Image inpainting is the task of filling in a removed or masked region of an image with content that fits the surrounding scene. The model takes two inputs: the original image and a binary mask that marks which pixels need to be replaced. It outputs a filled version of the image that blends with the unmasked areas.
For filmmakers and VFX artists, inpainting handles a set of tasks that would otherwise require manual compositing work. Wire and rig removal, where support cables or motion control equipment appear in a shot, is among the most common production uses. Object removal cleans up set dressing mistakes, unwanted reflections, or artifacts at the frame edge. Matte painting extensions use inpainting to expand a background plate beyond its original frame. Digital makeup touchups and skin cleanup on high resolution scans also rely on inpainting pipelines.
The difference between inpainting models in practice is rarely about whether the fill looks plausible but whether it looks right at the edges. A fill that generates convincing content inside the mask but produces visible seams at the boundary fails in production. Moebius is specifically benchmarked on edge coherence as part of its ECCV evaluation, which is the detail that matters for professional output.
Mask quality also determines output quality. An imprecise mask that clips the edge of a wire or cuts into an actor's hair will produce artifacts regardless of the model. Production inpainting workflows typically pair an inpainting model with a segmentation tool that generates accurate masks from the original frame. The Moebius repository documentation covers compatible mask generation approaches.
An inpainting model processes only the pixels the mask specifies. The rest of the frame passes through unchanged. This means the model's quality is evaluated only on the region being filled, which makes per-region quality comparisons between models straightforward: they are running on identical inputs and producing fills in identical masked areas.
0.22B Parameters, FLUX.1-Fill-Dev Level Results
The comparison to FLUX.1-Fill-Dev is the center of the Moebius technical argument. FLUX.1-Fill-Dev is the current standard reference for high quality image inpainting using diffusion models. It produces strong results across a wide range of subject types and mask shapes, and it runs on systems with substantial GPU memory.
Moebius matches that quality on the CelebA-HQ, FFHQ, and Places2 benchmark datasets, which cover face images and natural scenes across a wide range of scales and scene types. Matching FLUX.1-Fill-Dev on CelebA-HQ and FFHQ (face-specific datasets) is a harder task than matching on generic scenes, because face inpainting requires precise edge alignment and texture coherence at fine detail.
The 54x parameter gap is what makes this comparison notable. Prior work on lightweight inpainting models typically shows a quality tradeoff in the 5 to 15 percent range on standard metrics. Moebius claims to close that gap to within measurement noise on the evaluated benchmarks. Whether it holds under all production conditions, including very large masks, complex textures, or high resolution crops, requires independent evaluation beyond the paper's scope.
The Architecture
The Moebius pipeline uses an approach that progresses from coarse to fine spatial resolution, combined with efficient attention mechanisms that reduce memory and compute requirements without degrading output quality.
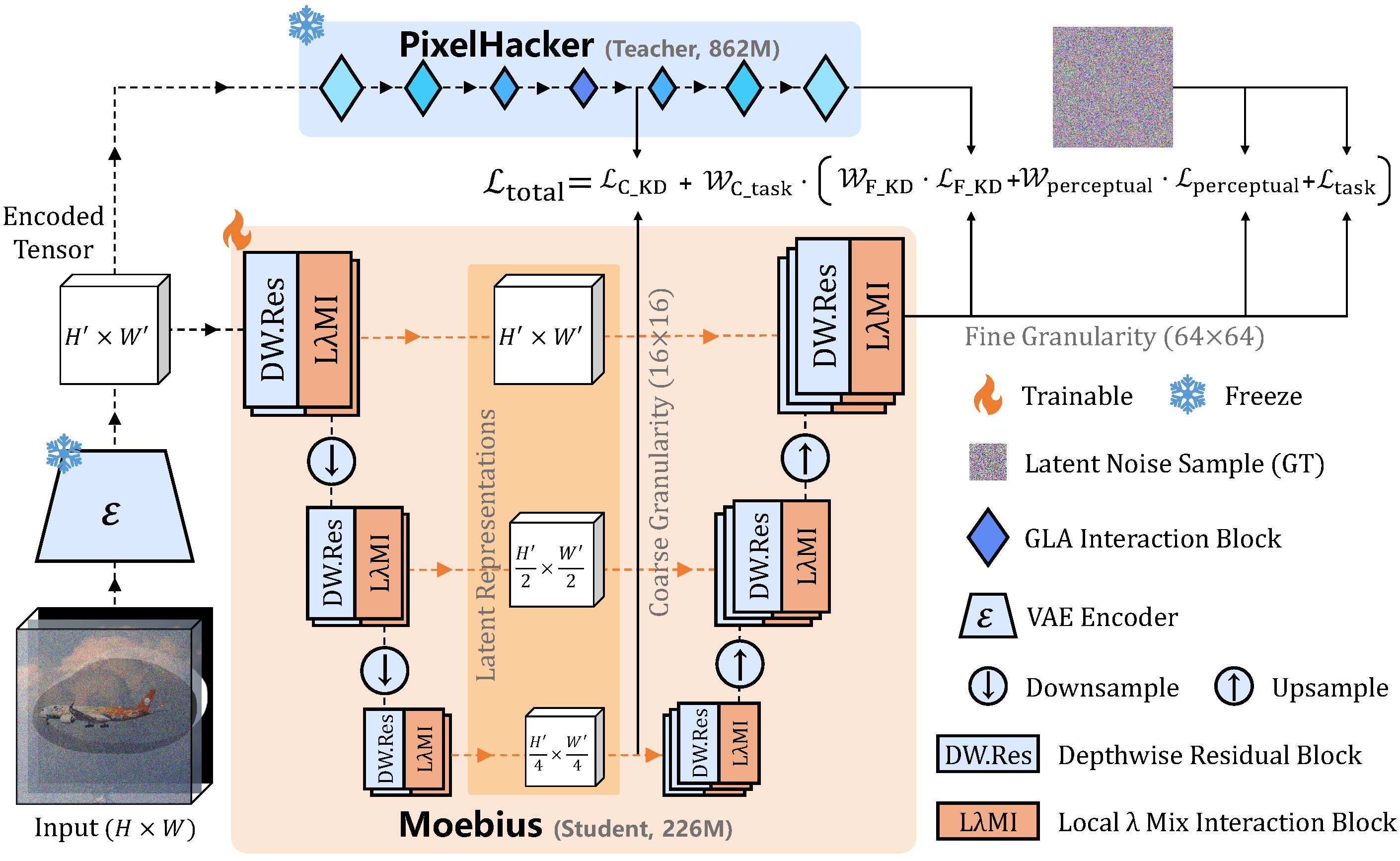
The design starts from a small base model rather than pruning a large one, which is a meaningful architectural decision. Pruned models often retain quality on distribution while degrading on edge cases where the full model's parameter count provided redundancy. A model trained from scratch at small scale tends to generalize differently, and the ECCV benchmark results reflect evaluation on test data held out from training, not just performance on familiar training distributions.
The lightweight architecture also enables faster iteration during inference. Because fewer parameters need to be loaded and processed per forward pass, the 15x speed advantage over FLUX.1-Fill-Dev is not an approximation: it reflects actual reduction in compute operations, not an optimization trick applied at the output layer.
Natural Scene Inpainting
The following comparison shows Moebius applied to a natural scene, with the masked input alongside the model's output.

Masked input

Moebius output
Natural scene comparison. Source: Moebius (HUST / VIVO AI Lab, ECCV 2026)
The fill extends the surrounding texture and lighting conditions into the masked region without visible boundary artifacts in the example. Natural scenes are a harder evaluation category than faces because irregular textures, foliage, and lighting variation across the frame create opportunities for the model to produce plausible but locally inconsistent fills. The Places2 benchmark specifically tests on these conditions.
Research Context: HUST and VIVO AI Lab
HUST (Huazhong University of Science and Technology) is a major Chinese research university with a productive computer vision output. Its computer vision group has contributed models across multiple tasks in recent years, and this paper continues that output with a focus on practical efficiency. VIVO AI Lab is the research division of Chinese smartphone manufacturer VIVO, which has funded applied computer vision research specifically targeted at mobile and edge deployment.
That institutional combination matters for understanding what Moebius was designed to do. A university group produces research models. An industry lab producing research in partnership with that group has reasons to care about models running efficiently on hardware with limited compute. The 0.22B parameter target is consistent with deployment on hardware outside datacenters, even though the paper's benchmarks focus on standard GPU evaluation.
What the Speed Difference Means in Practice
Fifteen times faster inference translates directly into iteration speed during production. A task that required waiting several minutes per fill on a system running FLUX.1-Fill-Dev can complete in seconds with Moebius. For VFX pipelines that process dozens or hundreds of frames requiring cleanup, the throughput difference is significant.
The smaller memory footprint is equally relevant. FLUX.1-Fill-Dev requires substantial VRAM to run at production resolution. Moebius's 0.22B parameter count reduces that requirement substantially, opening up inpainting workflows on hardware configurations that could not run the full FLUX model. The paper does not specify a minimum VRAM requirement, so exact hardware compatibility requires testing on a given system.
For filmmakers using the AI FILMS Studio image workspace, still frame cleanup and generation tasks are available through the platform's image models. Moebius represents the open source path for teams that need local inpainting with full control over the model and output pipeline.
Context: Inpainting in the Broader Diffusion Model Landscape
FLUX.1-Fill-Dev established the current quality ceiling for open source inpainting. Before Moebius, achieving that level of output required running the full 11.9B model or accepting a measurable quality reduction from smaller alternatives. The FLUX.2 release extended Black Forest Labs' generation capabilities across multiple tasks, and inpainting remained the most compute-intensive part of that workflow.
Moebius enters the field with a specific claim: comparable inpainting quality at a fraction of the cost. The ECCV peer review provides meaningful validation. ECCV is a competitive venue and acceptance requires the paper's claims to hold up under expert evaluation of the methodology, benchmarks, and reproducibility. That is a higher bar than a technical report published without peer review or a model card without independent evaluation.
For teams working on production video cleanup, Moebius pairs naturally with video object removal tools. EffectErase removes objects from video frames along with their secondary effects, including shadows, reflections, and surface deformations. A workflow that uses EffectErase for video object removal and Moebius for still frame cleanup covers both motion and static inpainting needs from a single lightweight pipeline.
License and Access
Moebius weights are released under the MIT license on HuggingFace. The model code is released under the Apache 2.0 license on GitHub. Both licenses permit commercial use. The model weights and code can be downloaded directly without an API key or platform subscription.
The MIT license on the weights is the more permissive of the two. It places no conditions on redistribution or modification. The Apache 2.0 license on the code is also commercially permissive but requires attribution and preservation of license notices when distributing modified versions. For production integration, both licenses are workable for commercial pipelines.
No HuggingFace Space with a live interactive demo was available at the time of publication. Model weights, inference code, and architecture documentation are available at the links in Sources below. The project page at hustvl.github.io/Moebius includes visual comparisons across multiple benchmark categories.
The paper was submitted to arXiv on June 17, 2026. Code and weights were released on June 18, 2026. The model is accepted at ECCV 2026, the European Conference on Computer Vision, one of the field's primary venues for image processing and generation research, where all papers undergo peer review before acceptance.


Sources
arXiv: Moebius: Towards Efficient and High-Quality Image Inpainting GitHub: hustvl/Moebius Hugging Face: hustvl/Moebius Project Page: hustvl.github.io/Moebius
Continue Reading
.jpg?w=3840)


Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3
- OpenAI Sora 2
- Kling 3.0
- Kling O1
- Google Veo 3.1
- LTX 2.3
- Kling O1
- Hailuo AI
- Luma Ray
- Kling 3.0 Motion
- Topaz Upscaler
- InfiniteTalk Face Swap
Image & Edit
- AI Character
- AI Actor
- Art Generator
- Text to Image
- Image to Image
- Draw to Edit
- Image Training
- Remove Background
- Image Enhancer
- MidJourney 8.0
- OpenAI GPT Image 2.0
- Kling Image 3.0
- NanoBanana Pro
- Minimax Image
- NanoBanana 2
- Kling Omni 3
- FLUX 2
- WAN 2.6
- Z-Image
- SeedEdit 3.0
- GLM-Image
- Omnigen 2
- Seedream 4.5
- Background Erase Network 2 (BEN2)