MOSS-SoundEffect v2.0: Open Source Sound Design at Broadcast Quality

Share this post:
MOSS-SoundEffect v2.0: Open Source Sound Design at Broadcast Quality
The OpenMOSS Team released MOSS-SoundEffect v2.0 on May 26, 2026, a 1.3 billion parameter diffusion model that generates targeted sound effects and environmental audio from text descriptions under Apache 2.0. The model outputs at 48 kHz, above the 44.1 kHz output of most professional AI audio tools released to date.
MOSS-SoundEffect v2.0 promotional demo from the OpenMOSS Team
What It Generates
MOSS-SoundEffect v2.0 covers the categories most relevant to film sound design. Natural environments include rain, wind, forest, and ocean audio. Urban scenes extend to traffic, crowds, and construction.
The model also handles animal sounds, human action audio, and percussive clips. Each generation runs up to 30 seconds with controllable duration. Both English and Chinese text prompts are supported.
Architecture and Specifications
The model uses a Diffusion Transformer (DiT) architecture trained with a Flow Matching objective. Text conditioning runs through a Qwen3-1.7B encoder; audio encoding and decoding are handled by a DAC VAE codec. At 1.3 billion parameters, the model is comparable in scale to other production-grade open source audio releases.

48 kHz and Broadcast Delivery
The 48 kHz output rate is the specification that most clearly separates MOSS-SoundEffect v2.0 from current peers. Stable Audio 3, released three days earlier by Stability AI, outputs at 44.1 kHz, the CD standard for consumer audio. MOSS-SoundEffect v2.0 outputs at 48 kHz, which matches the delivery specification for theatrical and broadcast audio set by the Society of Motion Picture and Television Engineers.
That distinction has a practical consequence. Audio from MOSS-SoundEffect v2.0 integrates directly into professional post production pipelines without sample rate conversion, removing a step that can introduce minor artefacts in DaVinci Resolve, Pro Tools, or similar tools.
For Foley and Sound Design
MOSS-SoundEffect v2.0 generates custom Foley and ambience assets directly from a text description, with no sound library required. A filmmaker building a crowd scene or an exterior ambience writes a description; the model returns audio at broadcast quality ready for the edit.
The scope is narrower than music generation models but higher in output fidelity for targeted sound design. HunyuanVideo Foley handles audio generation synchronized to existing video; MOSS-SoundEffect v2.0 operates from text alone, without requiring a video reference. The two models address different points in the post production audio workflow.
License and Access
MOSS-SoundEffect v2.0 is released under Apache 2.0. Commercial use, redistribution, and modification are all permitted without revenue thresholds or additional licensing steps. The weights are hosted on HuggingFace under the OpenMOSS-Team organization and the source code is available in the MOSS-TTS repository on GitHub.
The OpenMOSS Team is affiliated with Fudan University and has published audio generation research under open source terms since its earlier MOSS language model work.
For cloud-based music generation alongside sound effects, Suno in AI FILMS Studio produces complete vocal and instrumental tracks from text prompts in the same session.
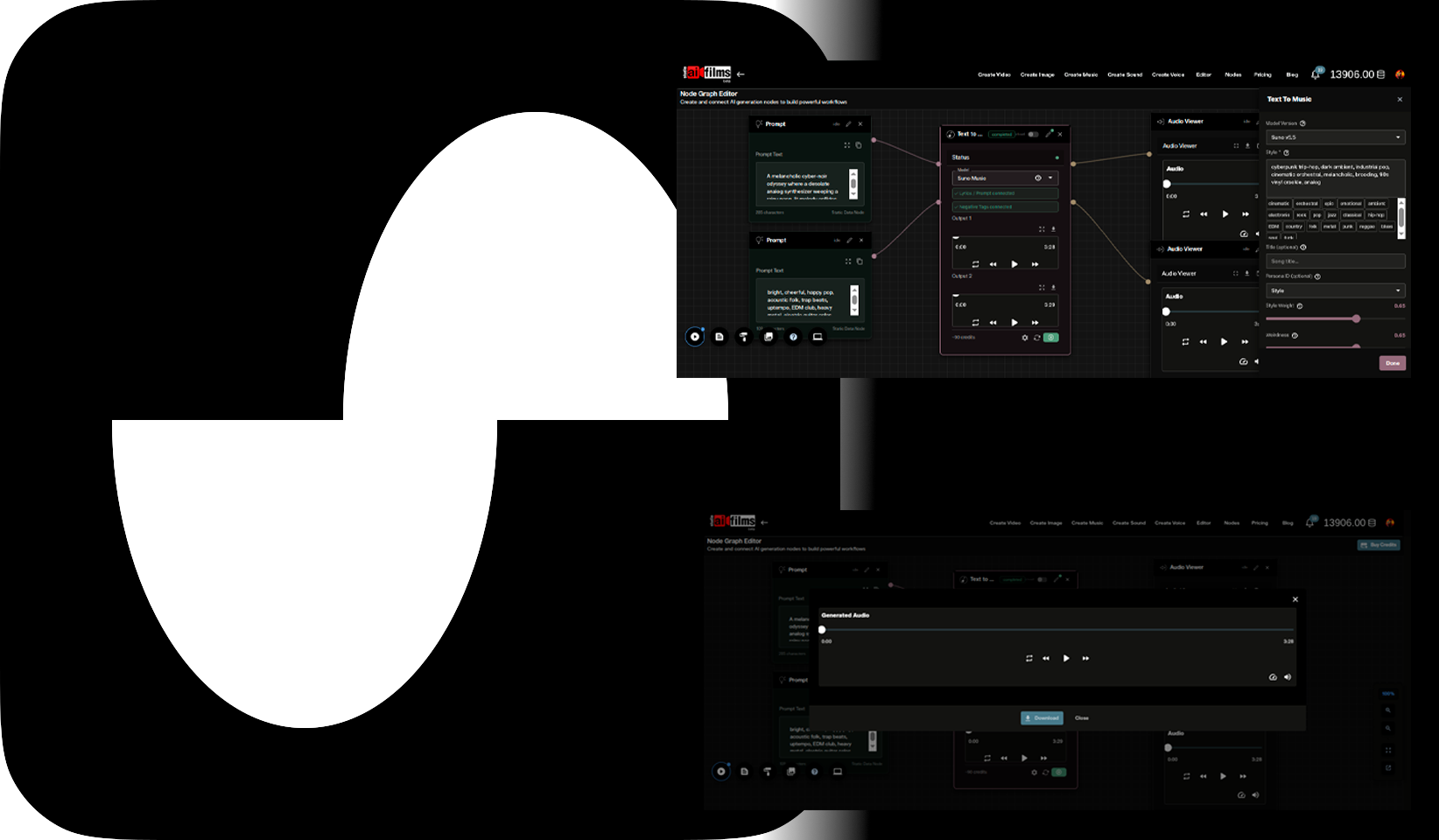
Filmmakers can generate sound effects and ambience for their projects in the AI FILMS Studio sound workspace.


OpenMOSS followed MOSS-SoundEffect with MOSS-Audio, a broader foundation model that understands and reasons about speech, environmental sound, and music. Where MOSS-SoundEffect generates audio from text, MOSS-Audio analyzes existing recordings and produces written explanations of what it finds. The formal technical report was published June 1, 2026 under Apache 2.0. The team completed the open source pipeline in June 2026 with MOSS-TTS Local Transformer v1.5, a 5B parameter voice cloning model generating 48 kHz stereo speech in 31 languages with explicit dialogue timing control.
Sources
HuggingFace: OpenMOSS-Team/MOSS-SoundEffect-v2.0 GitHub: OpenMOSS/MOSS-TTS License: Apache 2.0
Continue Reading

_(53532289710)_(cropped2).jpg?w=3840)
Video & LipSync
- Video Generator
- Text to Video
- Image to Video
- Start-End Frame to Video
- Draw to Video
- Motion Control
- Video Enhancer
- Video Upscaler
- Video to Video LipSync
- Audio to Video LipSync
- Image to Video LipSync
- Video FaceSwap
- Seedance 2
- Vidu Q3 Pro
- Gemini Omni
- Google Veo 3.1
- Kling 3.0 Pro
- LTX 2.3
- Happy Horse 1.1
- Kling 3.0 Motion
- ByteDance Upscaler
- InfiniteTalk
- InsightFace